딥러닝) 텐서플로우3 - 모델 정규화, 콜백, 전이학습
1. 모델 정규화 기법
-
✨왜 모델 정규화가 필요한가?
- 과적합(Overfitting)을 해결하고 일반화 성능을 향상시키기 위함
-
✨과적합(Overfitting) 발생 상황
-
모델 복잡성이 높을 때 : 모델의 은닉층이 많아, 파라미터 개수가 많아질 때(
L1, L2규제,드롭아웃) -
가중치 초깃값의 영향으로 일부 가중치가 큰 수를 가지게 될때(가중치 초기화,배치정규화) -
학습 데이터가 부족할 때(
데이터 증강) -
데이터 노이즈가 많을 때 : 이상치가 많을 때(데이터 전처리 후
증강) -
학습 횟수가 많을 때 : epochs가 매우 많을 때(
콜백 함수)- 📌 각 상황에 맞는 대표적인 기법을 연결한 것일 뿐, 실제 상황에서 필요한 정규화 기법은 다를 수 있습니다.
-
1) L1, L2 규제 : 가중치 크기를 작게 만든다.
- L1 규제(Lasso) : 모델 가중치 벡터의 절댓값 합을 손실 함수에 추가 → 작은 가중치를 0으로 만드는 경향(특징 선택 효과)
y : 실제값
$hat_{y}$ : 예측값
$\lambda$ : 제약정도(하이퍼파라미터)
N : 해당 레이어의 가중치 개수
$w_{i}$ : 가중치
- L2 규제(Ridge) : 모델 가중치 벡터의 제곱합을 손실 함수에 추가 → 모든 가중치 크기를 줄이는 경향(특징 억제 효과)
y : 실제값
$hat_{y}$ : 예측값
$\lambda$ : 제약정도(하이퍼파라미터)
N : 해당 레이어의 가중치 개수
$w_{i}$ : 가중치
- 단점 : 학습(역전파의 가중치 갱신)을 방해하는 성격이 강해, 학습이 덜되었다고 생각되어 많은 epochs를 유도하는 경향이 크다. sklearn의 회귀분석에서 자주 쓰이는 L1, L2규제이지만 딥러닝에서 자주 쓰이는 것을 못보았다.
- ✨코드 예시
import tensorflow as tf
# L1 규제
L1_layer = tf.keras.layers.Dense(32, activation='relu', kernel_regularizer=tf.keras.regularizers.l1(0.01)) ## 0.01은 lambda값
# L2 규제
L2_layer = tf.keras.layers.Dense(32, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.01)) ## 0.01은 lambda값
2) 드롭아웃(DropOut)
- 1
epochs당 일부 신경망을 랜덤하게 삭제하면서 학습하는 방법(비율 설정 필요)
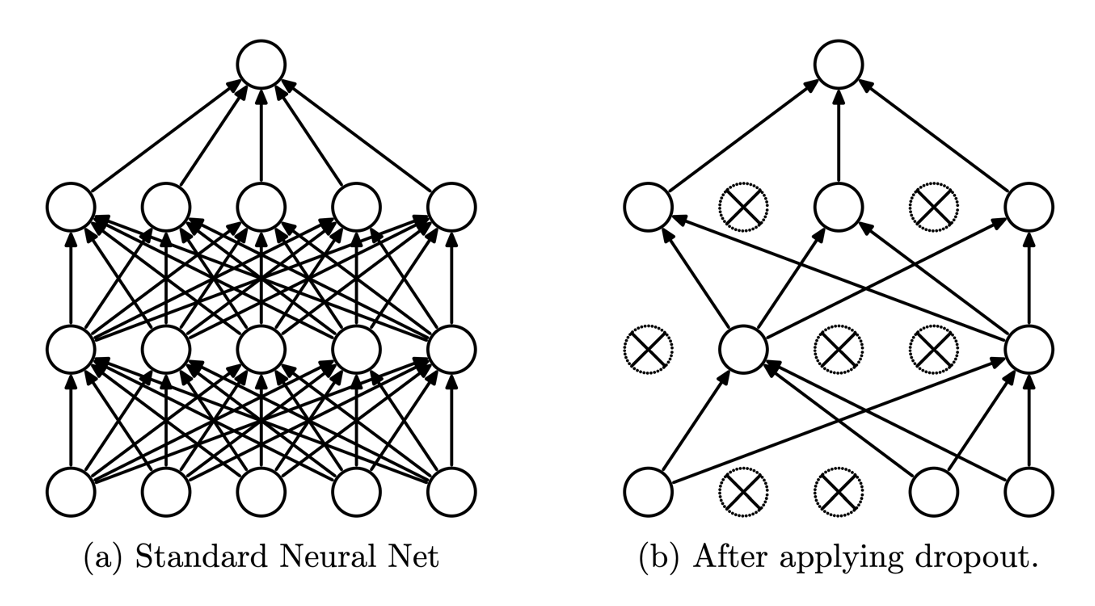
-
역할 : 특정 노드 사이의 관계를 불필요하게 강해지는 것을 막는다. 다른 여러 모델들을 통해 결과를 도출하는
앙상블 학습의 효과를 볼 수 있다. -
단점 : 1
epochs당 갱신되는 가중치의 숫자는 줄어드므로 많은 epochs를 유도하는 경향이 크다라 생각된다. 그러나 개인적으로 추후 서술할 callback함수 중 early stopping가 더불어 같이 사용하면 좋은 시너지를 낸다고 ‘개인적으로’ 생각한다.
- ✨코드 예시
import tensorflow as tf
# DropOut(적용시킬 레이어 다음으로 모델에 추가하면 된다.)
DropOut = tf.keras.layers.Dropout(0.3) ## 30%의 노드 삭제(0.3~0.5 숫자를 많이한다.)
3) 가중치 초기화
- ✨왜 랜덤하게 배정될
가중치 초기값이 매우 중요한가? 두가지 gif로 비교해보겠다.


- 수렴속도에서부터 엄청난 차이를 보이고, 첫 번째 가중치의 경우
local minima에 빠질 위험 또한 존재한다. 이를 위한 가중치 조절법에 대해 바로 서술해보겠다.
(1) Xavier Initialize(With Sigmoid)
- 가중치 표준편차가 $\frac{1}{\sqrt{n}}$ 인 정규분포로 초기화하는 기법
-
가중치 표준편차가 1인 정규분포로 가중치 초기화 했을 때의 활성화값(출력값) 분포
- 활성화 값이 0, 1에 치우쳐져 있음 → Sigmoid함수 특성 상, 기울기 값이 작아지다 사라지는 기울기 소실(Vanishing Gradient) 발생 → 가중치 갱신 불가

-
가중치 표준편차가 0.01인 정규분포로 가중치 초기화 했을 때의 활성화값(출력값) 분포
- 활성화 값이 0.5에 치우쳐져 있음 → 비슷한 값만 도출 됨 → 표현력 제한 이슈

-
✨Xavier 초깃값 활용 시 활성화값(출력값) 분포
- 균일한 분포의 활성화 값(일그러짐은 Sigmoid 대신 tanh함수를 사용하면 개선된다.)

(2) He Initialize(With ReLU)
- 가중치 표준편차가 $\sqrt{\frac{2}{n}}$ 인 정규분포로 초기화하는 기법
-
가중치 표준편차가 0.01인 정규분포로 가중치 초기화 했을 때의 활성화값(출력값) 분포
- 활성화 값이 0에 치우쳐져 있음 → 기울기 소실(Vanishing Gradient) 발생 → 가중치 갱신 불가
-
Xavier 초깃값 활용 시 활성화값(출력값) 분포
- 층이 깊어질때마다 활성화 값이 치우침 → 기울기 소실(Vanishing Gradient) 발생 → 가중치 갱신 불가
-
He 초깃값 활용 시 활성화값(출력값) 분포
- 층이 깊어져도 균일한 분포의 활성화 값

-✨ MNIST 데이터셋으로 본 가중치 초깃값 성능
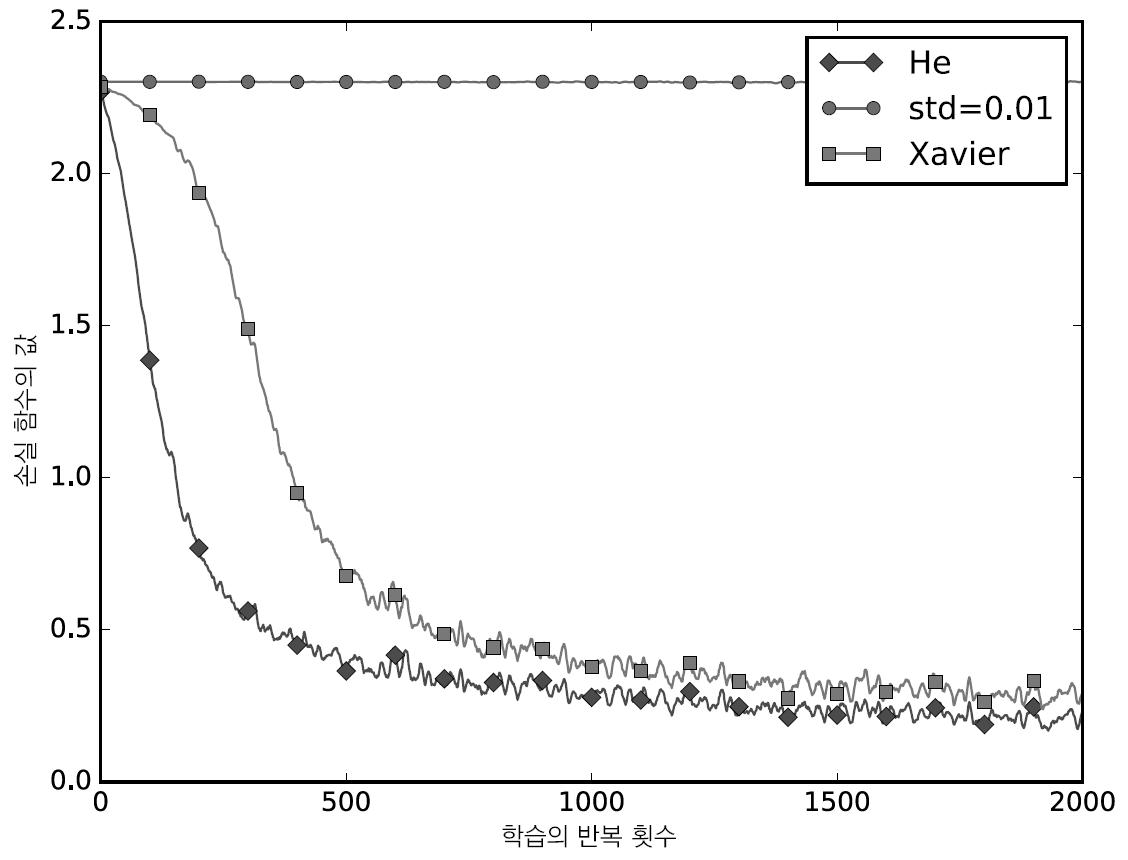
-✨ 코드 예시
# Xavier 초기화 레이어
Xavier_layer = tf.keras.layers.Dense(32, kernel_initializer=tf.keras.initializers.GlorotNormal(seed=None), activation='sigmoid')
# He 초기화 레이어
He_layer = tf.keras.layers.Dense(32, kernel_initializer=tf.keras.initializers.HeNormal(seed=None), activation='relu')
4) 배치 정규화
(1) 배치 학습(Batch Learning)
-
✨AI학습에서 왜 GPU의 성능이 거론되는가?
GPU는이미지라는tensor처리를 위해 고안된 하드웨어 → 병렬 방식의 학습에 유리하다. →하나씩보다 한꺼번에 학습하는 것이 좋다.
-
✨✨배치 학습(Batch Learning) 또는 미니 배치 학습(Mini-Batch)이란?
-
배치 학습: 모든 데이터를 한번에 학습 -
미니 배치 학습: GPU가 가능한 만큼 잘라서 뭉텅이로 학습 -
장점 : 하나씩 학습하는 Stochastic 방식보다 최적의 가중치 수렴이 안정적으로 이루어진다.
-

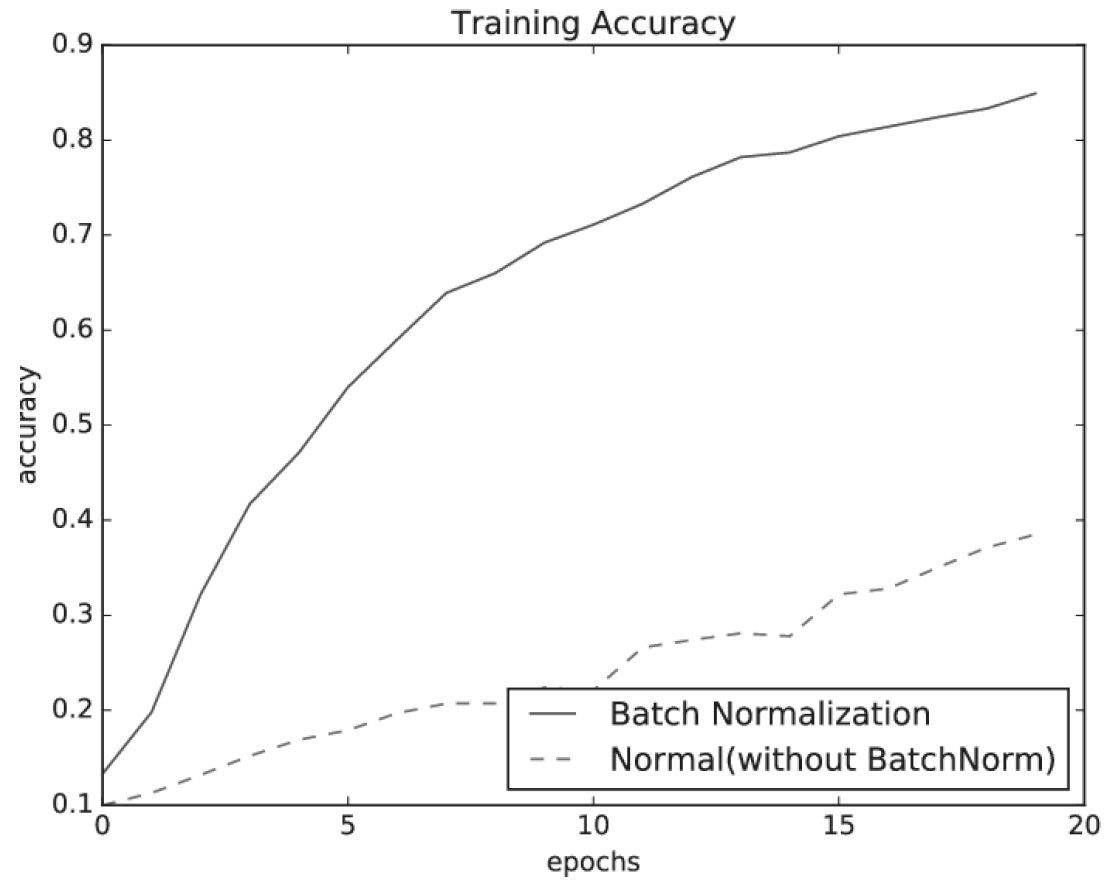
(2) 배치 정규화(Batch Normalization)
- 미니배치 단위로 평균 0, 분산 1이 되도록 정규화 → 배치 학습 시, 가중치 초기화처럼 각 층의 활성화값이 균일하게 분포하도록 하는 기법(기울기가 개선되어 학습속도 개선)
$\mu_{B}$ : 미니배치 단위의 가중치 평균
m : 미니배치 단위의 가중치 개수
$x_{i}$ : 가중치
$\sigma_{B}^2$ : 미니배치 단위의 가중치 분산
$\varepsilon$ : 매우 작은 수(분모 0 방지) $\approx 10^{-5}$
$\hat{x_{i}}$ : 배치 정규화된 가중치
- ✨코드 예시
import tensorflow as tf
# 배치 정규화 (적용시킬 레이어 다음으로 모델에 추가하면 된다.)
batch_layer = tf.keras.layers.BatchNormalization()
# 모델 정의 후 학습 시 배치 적용
history = model.fit(x_train, y_train, epochs=20, batch_size=32)
5) 데이터 증강
-
데이터의 핵심 특징(feature)는 간직한 채, 노이즈(noise)[작은 변화]를 더하여 데이터셋을 확장하는 방법
-
장점 : 추가적인 데이터 확보의 장점을 얻을 수 있다.(데이터가 적을 때 특히 유용)
-
단점 : 기존 데이터에서 크게 확장되지 않은 데이터만을 확보하게 되는 단점이 있다.
-
(1) 이미지 증강 기법
- 📌출처 : https://kh-kim.github.io/
① 노이즈 추가

② 회전과 이동, 뒤집기
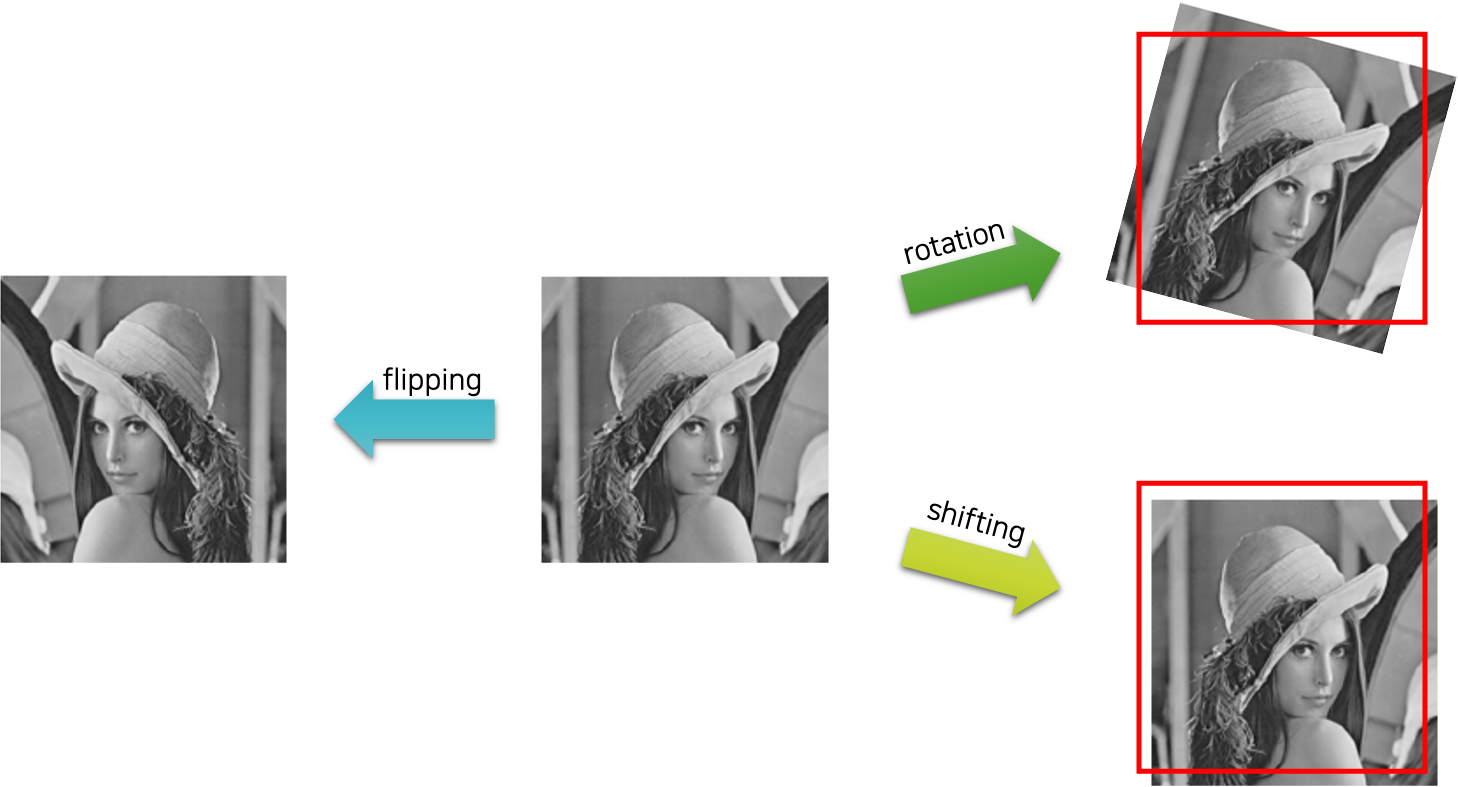
③ 생성 모델을 활용한 데이터 증강

(2) 텍스트 증강 기법
① 단어의 생략

② 단어 교환

③ 단어 이동

2. 콜백 함수
- 콜백(Callbacks)이란? 용이한 학습을 위한 도구 중 하나
(1) ModelCheckpint
-
정기적으로 모델의 체크포인트를 저장하여
복구가능하도록 함(장시간 학습 시 부득이하게 종료되는 것을 대비) -
✨코드 예시
# 체크포인트 파일 지정
check_point = tf.keras.callbacks.ModelCheckpoint('check_point.h5', monitor='val_loss', save_best_only=True)
## 좋은 모델 평가 기준 : Validation Loss
## 최고 모델만 저장할 것인가 : True
(2) EarlyStopping
-
성능이 한동안 개선되지 않을 경우(monitor파라미터로 성능 기준 설정 가능) 자동으로 학습을 중단(epochs 조절에 유용)
-
✨코드 예시
## patience만큼 성능 미개선 시 학습 중단
early_stopping = tf.keras.callbacks.EarlyStopping(patience=3, monitor='val_loss',
restore_best_weights=True)
## 성능 평가 기준 : Validation Loss
## 최고의 가중치로 복구할 것인가 : True
(3) LearningRateScheduler
-
학습 동안 학습률(learning_rate)를 동적으로 변경(옵티마이저의 개선 기능)
-
✨코드 예시
## 스케줄러 정의
def scheduler(epoch, learning_rate):
if epoch < 10:
return learning_rate
else:
return learning_rate * tf.math.exp(-0.1)
## 스케줄러 선언
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(scheduler)
(4) Tensorboard
-
모델의 경과를 모너터링할 때 사용
-
✨코드 예시
## 텐서보드 정의
log_dir = './logs'
tensor_board = [tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, write_graph=True, write_images=True)]
## 학습 후 확인할 때
%load_ext tensorboard
%tensorboard --logdir {log_dir}
✨코드 예시
-
데이터 및 모델 준비- fashion_mnist 구분 하기(Image classification)
# 데이터 불러오기
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# MinMaxScale
x_train = x_train/255
x_test = x_test/255
# # 차원 추가
x_train = x_train.reshape(-1, x_train.shape[1], x_train.shape[2], 1) ## 1차원 생성
x_test = x_test.reshape(-1, x_test.shape[1], x_test.shape[2], 1) ## 1차원 생성
# 모델정의
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3,3), padding='same', activation='relu', name='conv2d_1', input_shape=(28,28,1)))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2), name='Maxpool_1'))
model.add(tf.keras.layers.Conv2D(16, kernel_size=(5,5), padding='same', activation='relu', name='conv2d_2'))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2), name='Maxpool_2'))
model.add(tf.keras.layers.Flatten(name='flatten'))
model.add(tf.keras.layers.Dense(64, activation='relu', name='dense_1'))
model.add(tf.keras.layers.BatchNormalization(name='BatchNormalization_1'))
model.add(tf.keras.layers.Dropout(0.3, name='Dropout_1'))
model.add(tf.keras.layers.Dense(32, activation='relu', name='dense_2'))
model.add(tf.keras.layers.Dense(10, activation='softmax', name='output'))
model.summary()
Model: "sequential_9"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 32) 320
Maxpool_1 (MaxPooling2D) (None, 14, 14, 32) 0
conv2d_2 (Conv2D) (None, 14, 14, 16) 12816
Maxpool_2 (MaxPooling2D) (None, 7, 7, 16) 0
flatten (Flatten) (None, 784) 0
dense_1 (Dense) (None, 64) 50240
BatchNormalization_1 (Batc (None, 64) 256
hNormalization)
Dropout_1 (Dropout) (None, 64) 0
dense_2 (Dense) (None, 32) 2080
output (Dense) (None, 10) 330
=================================================================
Total params: 66042 (257.98 KB)
Trainable params: 65914 (257.48 KB)
Non-trainable params: 128 (512.00 Byte)
_________________________________________________________________
콜백 함수 정의
# 콜백 함수 정의
## 체크포인트
check_point = tf.keras.callbacks.ModelCheckpoint('check_point.h5', monitor='val_loss', save_best_only=True)
## 얼리스타핑
early_stopping = tf.keras.callbacks.EarlyStopping(patience=3, monitor='val_loss',
restore_best_weights=True)
## 스케줄러 정의
def scheduler(epoch, learning_rate):
if epoch < 10:
return learning_rate
else:
return learning_rate * tf.math.exp(-0.1)
## 스케줄러 선언
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(scheduler)
## 텐서보드
log_dir = './logs'
tensor_board = [tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, write_graph=True, write_images=True)]
모델 컴파일
# 모델 컴파일
model.compile(loss='sparse_categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])
모델 학습 : 콜백 함수 포함
history = model.fit(x_train, y_train,
epochs=30,
batch_size=16,
validation_split=0.2,
callbacks=[check_point, early_stopping, lr_scheduler, tensor_board])
Epoch 1/30 WARNING:tensorflow:From C:\Users\Kimmingee\anaconda3\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead. WARNING:tensorflow:From C:\Users\Kimmingee\anaconda3\Lib\site-packages\keras\src\engine\base_layer_utils.py:384: The name tf.executing_eagerly_outside_functions is deprecated. Please use tf.compat.v1.executing_eagerly_outside_functions instead. 2992/3000 [============================>.] - ETA: 0s - loss: 0.5173 - accuracy: 0.8202
C:\Users\Kimmingee\anaconda3\Lib\site-packages\keras\src\engine\training.py:3103: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
3000/3000 [==============================] - 16s 5ms/step - loss: 0.5172 - accuracy: 0.8202 - val_loss: 0.3298 - val_accuracy: 0.8802 - lr: 0.0010 Epoch 2/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.3533 - accuracy: 0.8731 - val_loss: 0.3017 - val_accuracy: 0.8880 - lr: 0.0010 Epoch 3/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.3092 - accuracy: 0.8919 - val_loss: 0.2708 - val_accuracy: 0.9012 - lr: 0.0010 Epoch 4/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.2867 - accuracy: 0.8991 - val_loss: 0.2737 - val_accuracy: 0.8991 - lr: 0.0010 Epoch 5/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.2723 - accuracy: 0.9022 - val_loss: 0.2751 - val_accuracy: 0.9008 - lr: 0.0010 Epoch 6/30 3000/3000 [==============================] - 16s 5ms/step - loss: 0.2531 - accuracy: 0.9094 - val_loss: 0.2321 - val_accuracy: 0.9177 - lr: 0.0010 Epoch 7/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.2438 - accuracy: 0.9115 - val_loss: 0.2354 - val_accuracy: 0.9162 - lr: 0.0010 Epoch 8/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.2324 - accuracy: 0.9159 - val_loss: 0.2471 - val_accuracy: 0.9108 - lr: 0.0010 Epoch 9/30 3000/3000 [==============================] - 14s 5ms/step - loss: 0.2218 - accuracy: 0.9207 - val_loss: 0.2404 - val_accuracy: 0.9162 - lr: 0.0010
-
check_point함수로 지정된 경로에check_point.h5이 생성된 것을 확인 가능함 -
early stopping으로epochs가 지정된 30회가 아닌 9회에서 멈춘 것으로 확인
학습결과 시각화
plt.figure(figsize=(15,4))
plt.subplot(1,2,1)
plt.title('loss and val_loss')
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(1,2,2)
plt.title('accuracy and val_accuracy')
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.show()

모델 평가
model.evaluate(x_test, y_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.2572 - accuracy: 0.9086
[0.25719690322875977, 0.9085999727249146]
- test 데이터셋에 대해 90.86%의 정확도를 보이고 있다.
텐서보드 확인
%load_ext tensorboard
%tensorboard --logdir {log_dir}
-
epochs가 10회 이상을 넘지 않아learning_rate가 $10^{-3}$에서 변하지 않았음을 텐서보드를 통해 확인할 수 있었다.lr_scheduler가 아직 작동하지 않음
-
이렇듯 텐서보드를 실행하여 여러 요소들을 확인할 수 있다.(공부가 따로 필요한 부분이다.)
3. 전이 학습(Transfer Learning)
-
사실 이미 많은 사람들이 좋은 신경망, 좋은 가중치를 확보해둔 상태이다.
-
실질적으로 연구자가 아닌 입장에서 AI를 ‘효율적’으로 활용하기 위해서는
전이 학습만큼 중요한 게 없다고 본다.
1) 전이 학습(Transfer Learning)의 정의
- 사전 학습 모델(Pre-trained model)을 불러와 추가 학습을 시키는 개념(쉽게 말해 비슷한 분야의 모범생을 데리고와 알맞게 재교육 시키는 것)
2) Fine-tuning
- 사전 학습 모델(Pre-trained model)을 불러와 모델의 파라미터를 미세하게 조정하는 행위를 일컫음.
(1) Fine-tuning의 전략

-
상황1 : 크기가 크고 유사성이 작은 데이터 셋일 때 : 전략1(전체 모델을 학습)이 유리
-
상황2 : 크기가 크고 유사성이 높은 데이터 셋일 때 : 전략2(일부만 학습)이 유리
-
상황3 : 크기가 작고 유사성이 작은 데이터 셋일 때 : 전략2(일부만 학습)이 유리
-
상황4 : 크기가 작고 유사성이 높은 데이터 셋일 때 : 전략3(마지막부분만 학습)이 유리
- ✨ 물론 상황에 따라 자의적으로 선택하는 것이 더 중요!
✨ 코드 예시
(1) 사용한 모델 저장 및 불러오기
# 선언된 model 저장
model.save("fashion_minist.h5")
# 모델 불러오기
Mymodel = tf.keras.models.load_model("fashion_minist.h5")
Mymodel.summary()
Model: "sequential_9"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 32) 320
Maxpool_1 (MaxPooling2D) (None, 14, 14, 32) 0
conv2d_2 (Conv2D) (None, 14, 14, 16) 12816
Maxpool_2 (MaxPooling2D) (None, 7, 7, 16) 0
flatten (Flatten) (None, 784) 0
dense_1 (Dense) (None, 64) 50240
BatchNormalization_1 (Batc (None, 64) 256
hNormalization)
Dropout_1 (Dropout) (None, 64) 0
dense_2 (Dense) (None, 32) 2080
output (Dense) (None, 10) 330
=================================================================
Total params: 66042 (257.98 KB)
Trainable params: 65914 (257.48 KB)
Non-trainable params: 128 (512.00 Byte)
_________________________________________________________________
모델 확인
Mymodel.evaluate(x_test, y_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.2572 - accuracy: 0.9086
[0.25719690322875977, 0.9085999727249146]
- 동일하게 90.86%의 정확도를 내는 것으로 확인됨.
(2) 텐서플로우 제공 모델 불러오기
제공 모델 확인
dir(tf.keras.applications)
['ConvNeXtBase', 'ConvNeXtLarge', 'ConvNeXtSmall', 'ConvNeXtTiny', 'ConvNeXtXLarge', 'DenseNet121', 'DenseNet169', 'DenseNet201', 'EfficientNetB0', 'EfficientNetB1', 'EfficientNetB2', 'EfficientNetB3', 'EfficientNetB4', 'EfficientNetB5', 'EfficientNetB6', 'EfficientNetB7', 'EfficientNetV2B0', 'EfficientNetV2B1', 'EfficientNetV2B2', 'EfficientNetV2B3', 'EfficientNetV2L', 'EfficientNetV2M', 'EfficientNetV2S', 'InceptionResNetV2', 'InceptionV3', 'MobileNet', 'MobileNetV2', 'MobileNetV3Large', 'MobileNetV3Small', 'NASNetLarge', 'NASNetMobile', 'RegNetX002', 'RegNetX004', 'RegNetX006', 'RegNetX008', 'RegNetX016', 'RegNetX032', 'RegNetX040', 'RegNetX064', 'RegNetX080', 'RegNetX120', 'RegNetX160', 'RegNetX320', 'RegNetY002', 'RegNetY004', 'RegNetY006', 'RegNetY008', 'RegNetY016', 'RegNetY032', 'RegNetY040', 'RegNetY064', 'RegNetY080', 'RegNetY120', 'RegNetY160', 'RegNetY320', 'ResNet101', 'ResNet101V2', 'ResNet152', 'ResNet152V2', 'ResNet50', 'ResNet50V2', 'ResNetRS101', 'ResNetRS152', 'ResNetRS200', 'ResNetRS270', 'ResNetRS350', 'ResNetRS420', 'ResNetRS50', 'VGG16', 'VGG19', 'Xception', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'convnext', 'densenet', 'efficientnet', 'efficientnet_v2', 'imagenet_utils', 'inception_resnet_v2', 'inception_v3', 'mobilenet', 'mobilenet_v2', 'mobilenet_v3', 'nasnet', 'regnet', 'resnet', 'resnet50', 'resnet_rs', 'resnet_v2', 'vgg16', 'vgg19', 'xception']
base_model로 불러오기
# weights(imagenet으로 학습된 모델 가중치 불러오기), include_top(학습된 모델 불러오기), input_shape정하기
base_model = tf.keras.applications.MobileNet(weights='imagenet', include_top=False, input_shape=(32,32,3))
Mymodel2 = tf.keras.models.Sequential()
Mymodel2.add(base_model)
Mymodel2.add(tf.keras.layers.Dense(10, activation='softmax'))
base_model.summary()
WARNING:tensorflow:`input_shape` is undefined or non-square, or `rows` is not in [128, 160, 192, 224]. Weights for input shape (224, 224) will be loaded as the default.
Model: "mobilenet_1.00_224"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_17 (InputLayer) [(None, 32, 32, 3)] 0
conv1 (Conv2D) (None, 16, 16, 32) 864
conv1_bn (BatchNormalizati (None, 16, 16, 32) 128
on)
conv1_relu (ReLU) (None, 16, 16, 32) 0
conv_dw_1 (DepthwiseConv2D (None, 16, 16, 32) 288
)
conv_dw_1_bn (BatchNormali (None, 16, 16, 32) 128
zation)
conv_dw_1_relu (ReLU) (None, 16, 16, 32) 0
conv_pw_1 (Conv2D) (None, 16, 16, 64) 2048
conv_pw_1_bn (BatchNormali (None, 16, 16, 64) 256
zation)
conv_pw_1_relu (ReLU) (None, 16, 16, 64) 0
conv_pad_2 (ZeroPadding2D) (None, 17, 17, 64) 0
conv_dw_2 (DepthwiseConv2D (None, 8, 8, 64) 576
)
conv_dw_2_bn (BatchNormali (None, 8, 8, 64) 256
zation)
conv_dw_2_relu (ReLU) (None, 8, 8, 64) 0
conv_pw_2 (Conv2D) (None, 8, 8, 128) 8192
conv_pw_2_bn (BatchNormali (None, 8, 8, 128) 512
zation)
conv_pw_2_relu (ReLU) (None, 8, 8, 128) 0
conv_dw_3 (DepthwiseConv2D (None, 8, 8, 128) 1152
)
conv_dw_3_bn (BatchNormali (None, 8, 8, 128) 512
zation)
conv_dw_3_relu (ReLU) (None, 8, 8, 128) 0
conv_pw_3 (Conv2D) (None, 8, 8, 128) 16384
conv_pw_3_bn (BatchNormali (None, 8, 8, 128) 512
zation)
conv_pw_3_relu (ReLU) (None, 8, 8, 128) 0
conv_pad_4 (ZeroPadding2D) (None, 9, 9, 128) 0
conv_dw_4 (DepthwiseConv2D (None, 4, 4, 128) 1152
)
conv_dw_4_bn (BatchNormali (None, 4, 4, 128) 512
zation)
conv_dw_4_relu (ReLU) (None, 4, 4, 128) 0
conv_pw_4 (Conv2D) (None, 4, 4, 256) 32768
conv_pw_4_bn (BatchNormali (None, 4, 4, 256) 1024
zation)
conv_pw_4_relu (ReLU) (None, 4, 4, 256) 0
conv_dw_5 (DepthwiseConv2D (None, 4, 4, 256) 2304
)
conv_dw_5_bn (BatchNormali (None, 4, 4, 256) 1024
zation)
conv_dw_5_relu (ReLU) (None, 4, 4, 256) 0
conv_pw_5 (Conv2D) (None, 4, 4, 256) 65536
conv_pw_5_bn (BatchNormali (None, 4, 4, 256) 1024
zation)
conv_pw_5_relu (ReLU) (None, 4, 4, 256) 0
conv_pad_6 (ZeroPadding2D) (None, 5, 5, 256) 0
conv_dw_6 (DepthwiseConv2D (None, 2, 2, 256) 2304
)
conv_dw_6_bn (BatchNormali (None, 2, 2, 256) 1024
zation)
conv_dw_6_relu (ReLU) (None, 2, 2, 256) 0
conv_pw_6 (Conv2D) (None, 2, 2, 512) 131072
conv_pw_6_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_pw_6_relu (ReLU) (None, 2, 2, 512) 0
conv_dw_7 (DepthwiseConv2D (None, 2, 2, 512) 4608
)
conv_dw_7_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_dw_7_relu (ReLU) (None, 2, 2, 512) 0
conv_pw_7 (Conv2D) (None, 2, 2, 512) 262144
conv_pw_7_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_pw_7_relu (ReLU) (None, 2, 2, 512) 0
conv_dw_8 (DepthwiseConv2D (None, 2, 2, 512) 4608
)
conv_dw_8_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_dw_8_relu (ReLU) (None, 2, 2, 512) 0
conv_pw_8 (Conv2D) (None, 2, 2, 512) 262144
conv_pw_8_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_pw_8_relu (ReLU) (None, 2, 2, 512) 0
conv_dw_9 (DepthwiseConv2D (None, 2, 2, 512) 4608
)
conv_dw_9_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_dw_9_relu (ReLU) (None, 2, 2, 512) 0
conv_pw_9 (Conv2D) (None, 2, 2, 512) 262144
conv_pw_9_bn (BatchNormali (None, 2, 2, 512) 2048
zation)
conv_pw_9_relu (ReLU) (None, 2, 2, 512) 0
conv_dw_10 (DepthwiseConv2 (None, 2, 2, 512) 4608
D)
conv_dw_10_bn (BatchNormal (None, 2, 2, 512) 2048
ization)
conv_dw_10_relu (ReLU) (None, 2, 2, 512) 0
conv_pw_10 (Conv2D) (None, 2, 2, 512) 262144
conv_pw_10_bn (BatchNormal (None, 2, 2, 512) 2048
ization)
conv_pw_10_relu (ReLU) (None, 2, 2, 512) 0
conv_dw_11 (DepthwiseConv2 (None, 2, 2, 512) 4608
D)
conv_dw_11_bn (BatchNormal (None, 2, 2, 512) 2048
ization)
conv_dw_11_relu (ReLU) (None, 2, 2, 512) 0
conv_pw_11 (Conv2D) (None, 2, 2, 512) 262144
conv_pw_11_bn (BatchNormal (None, 2, 2, 512) 2048
ization)
conv_pw_11_relu (ReLU) (None, 2, 2, 512) 0
conv_pad_12 (ZeroPadding2D (None, 3, 3, 512) 0
)
conv_dw_12 (DepthwiseConv2 (None, 1, 1, 512) 4608
D)
conv_dw_12_bn (BatchNormal (None, 1, 1, 512) 2048
ization)
conv_dw_12_relu (ReLU) (None, 1, 1, 512) 0
conv_pw_12 (Conv2D) (None, 1, 1, 1024) 524288
conv_pw_12_bn (BatchNormal (None, 1, 1, 1024) 4096
ization)
conv_pw_12_relu (ReLU) (None, 1, 1, 1024) 0
conv_dw_13 (DepthwiseConv2 (None, 1, 1, 1024) 9216
D)
conv_dw_13_bn (BatchNormal (None, 1, 1, 1024) 4096
ization)
conv_dw_13_relu (ReLU) (None, 1, 1, 1024) 0
conv_pw_13 (Conv2D) (None, 1, 1, 1024) 1048576
conv_pw_13_bn (BatchNormal (None, 1, 1, 1024) 4096
ization)
conv_pw_13_relu (ReLU) (None, 1, 1, 1024) 0
=================================================================
Total params: 3228864 (12.32 MB)
Trainable params: 3206976 (12.23 MB)
Non-trainable params: 21888 (85.50 KB)
_________________________________________________________________
Mymodel2.summary()
Model: "sequential_12"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
mobilenet_1.00_224 (Functi (None, 1, 1, 1024) 3228864
onal)
dense_20 (Dense) (None, 1, 1, 10) 10250
=================================================================
Total params: 3239114 (12.36 MB)
Trainable params: 3217226 (12.27 MB)
Non-trainable params: 21888 (85.50 KB)
_________________________________________________________________
(3) 전이학습
-
Mymodel의 추가 학습을 진행해보고자 한다.- 여기서 텐서플로우 제공 모델을 이용하지 않는 이유는, 기본적으로 3채널 이상의 이미지 분석을 요구하기도 하고,
28x28x1이라는 단순 이미지엔 단순한 모델이 과적합 문제를 안일으킬 가능성이 높기 때문이다.
- 여기서 텐서플로우 제공 모델을 이용하지 않는 이유는, 기본적으로 3채널 이상의 이미지 분석을 요구하기도 하고,
-
두 가지 전이학습 모델을 만들어보겠다.(이전 학습에서 어떤 부분이 더 학습이 진행되지 않았는 지 비교)
-
feature_model이라 새로 정의해
feature extractor : conv2d, pooling의 가중치만 업데이트한 모델 -
classifier_model이라 새로 정의해
classifier : dense의 가중치만 업데이트한 모델
-
모델 복사 후 두 가지 모델 세팅
## 모델 복사
feature_model = tf.keras.models.clone_model(Mymodel)
classifier_model = tf.keras.models.clone_model(Mymodel)
## 가중치 복사
feature_model.set_weights(Mymodel.get_weights())
classifier_model.set_weights(Mymodel.get_weights())
# feature_model(conv2d층만 빼고 가중치 업데이트 중지)
for i in feature_model.layers[4:] :
i.trainable = False
# feature_model(dense층만 빼고 가중치 업데이트 중지)
for j in classifier_model.layers[:4] :
j.trainable = False
모델 컴파일
feature_model.compile(loss='sparse_categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])
classifier_model.compile(loss='sparse_categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])
얼리스타핑
## 얼리스타핑
early_stopping = tf.keras.callbacks.EarlyStopping(patience=5, monitor='val_loss',
restore_best_weights=True)
모델 학습
feature_history = feature_model.fit(x_train, y_train,
epochs=30,
batch_size=16,
validation_split=0.2,
callbacks=[early_stopping])
Epoch 1/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.2086 - accuracy: 0.9238 - val_loss: 0.2378 - val_accuracy: 0.9163 Epoch 2/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.2024 - accuracy: 0.9267 - val_loss: 0.2328 - val_accuracy: 0.9174 Epoch 3/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.1957 - accuracy: 0.9285 - val_loss: 0.2288 - val_accuracy: 0.9192 Epoch 4/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.1938 - accuracy: 0.9290 - val_loss: 0.2332 - val_accuracy: 0.9174 Epoch 5/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.1873 - accuracy: 0.9315 - val_loss: 0.2286 - val_accuracy: 0.9196 Epoch 6/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.1846 - accuracy: 0.9327 - val_loss: 0.2313 - val_accuracy: 0.9172 Epoch 7/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.1812 - accuracy: 0.9334 - val_loss: 0.2345 - val_accuracy: 0.9180 Epoch 8/30 3000/3000 [==============================] - 13s 4ms/step - loss: 0.1786 - accuracy: 0.9350 - val_loss: 0.2322 - val_accuracy: 0.9188 Epoch 9/30 3000/3000 [==============================] - 12s 4ms/step - loss: 0.1754 - accuracy: 0.9371 - val_loss: 0.2428 - val_accuracy: 0.9174 Epoch 10/30 3000/3000 [==============================] - 16s 5ms/step - loss: 0.1726 - accuracy: 0.9373 - val_loss: 0.2325 - val_accuracy: 0.9219
classifier_history = classifier_model.fit(x_train, y_train,
epochs=30,
batch_size=16,
validation_split=0.2,
callbacks=[early_stopping])
Epoch 1/30 3000/3000 [==============================] - 9s 3ms/step - loss: 0.2211 - accuracy: 0.9215 - val_loss: 0.2214 - val_accuracy: 0.9218 Epoch 2/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.2100 - accuracy: 0.9243 - val_loss: 0.2316 - val_accuracy: 0.9193 Epoch 3/30 3000/3000 [==============================] - 9s 3ms/step - loss: 0.2031 - accuracy: 0.9277 - val_loss: 0.2262 - val_accuracy: 0.9197 Epoch 4/30 3000/3000 [==============================] - 9s 3ms/step - loss: 0.1993 - accuracy: 0.9290 - val_loss: 0.2372 - val_accuracy: 0.9162 Epoch 5/30 3000/3000 [==============================] - 9s 3ms/step - loss: 0.1946 - accuracy: 0.9300 - val_loss: 0.2226 - val_accuracy: 0.9212 Epoch 6/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.1884 - accuracy: 0.9313 - val_loss: 0.2206 - val_accuracy: 0.9189 Epoch 7/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.1842 - accuracy: 0.9321 - val_loss: 0.2267 - val_accuracy: 0.9208 Epoch 8/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.1844 - accuracy: 0.9331 - val_loss: 0.2272 - val_accuracy: 0.9223 Epoch 9/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.1817 - accuracy: 0.9334 - val_loss: 0.2296 - val_accuracy: 0.9221 Epoch 10/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.1812 - accuracy: 0.9335 - val_loss: 0.2335 - val_accuracy: 0.9197 Epoch 11/30 3000/3000 [==============================] - 8s 3ms/step - loss: 0.1765 - accuracy: 0.9353 - val_loss: 0.2384 - val_accuracy: 0.9199
학습 결과 시각화
plt.figure(figsize=(15,4))
plt.subplot(1,2,1)
plt.title('feature_model loss and val_loss')
plt.plot(feature_history.history['loss'], label='loss')
plt.plot(feature_history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(1,2,2)
plt.title('feature_model accuracy and val_accuracy')
plt.plot(feature_history.history['accuracy'], label='accuracy')
plt.plot(feature_history.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.show()

plt.figure(figsize=(15,4))
plt.subplot(1,2,1)
plt.title('classifier_model loss and val_loss')
plt.plot(classifier_history.history['loss'], label='loss')
plt.plot(classifier_history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(1,2,2)
plt.title('classifier_model accuracy and val_accuracy')
plt.plot(classifier_history.history['accuracy'], label='accuracy')
plt.plot(classifier_history.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.show()

모델 평가
Mymodel.evaluate(x_test, y_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.2572 - accuracy: 0.9086
[0.25719690322875977, 0.9085999727249146]
feature_model.evaluate(x_test, y_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.2489 - accuracy: 0.9148
[0.2489495873451233, 0.9147999882698059]
classifier_model.evaluate(x_test, y_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.2400 - accuracy: 0.9173
[0.23998825252056122, 0.9172999858856201]
- val_loss가 거의 유지된 채로 loss가 떨어져가고만 있다.
과적합의 위험이 있었던 것은 분명하지만 분명 추가 학습 이전 Mymodel의90.86%보단 개선되 결과를 둘다 보이는 것(feature_model :91.48%, classifier_model :91.73%)을 알 수 있다. 실제로는 직접 만든 모델보다도 이미 정의된 모델을 가져와 input_layer와 output_layer를 알맞게 정의하여 전이 학습을 진행하면 적은 리소스를 가지고도 정말 훌륭한 AI를 쉽게 만들어낼 수 있을 것이다.
댓글남기기