Scikit-learn(지도학습1) - 분류
1. 의사결정나무(DecisionTreeClassifier)
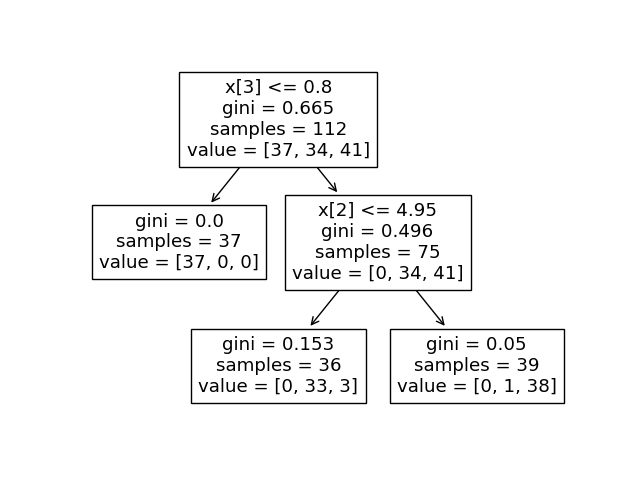
보기의 예시의 모델은 value에 [37, 34, 41]이 들어 있는 것으로 보아, 3가지 범주를 가지고 있고 RootNode에서 첫 번째에 해당하는 범주와 나머지 범주를 완벽히 분리해낸 것으로 보인다. 그리고 제일 밑 LeafNode에서 두 번재, 세 번째에 해당하는 범주 또한 거의 완벽히 분리된 것으로 나온다.
즉, 의사결정나무는 주어진 데이터 x값을 활용하여 스무고개 하듯, 계속 질문하는 과정을 통해 값들을 분류해나간다.(불순도가 낮아지는 방향을 향해 움직인다)
2. sklearn의 유방암 데이터를 이용한 의사결정나무 예시
1) x_train, y_train 학습데이터 생성, x_test, y_test 검증데이터 생성
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
x_train, x_test, y_train, y_test = train_test_split(
df.drop('target', axis=1),
df['target'],
test_size=0.3,
random_state=1)
- 학습데이터와 검증데이터를 굳이 나누어 제작하는 이유는, 모델의 학습은 학습데이터로만 시킨 뒤, 검증데이터를 통해 해당 모델을 평가하기 위함.
2) 정확도 검증
from sklearn.tree import DecisionTreeClassifier # 의사결정나무는 tree
from sklearn.metrics import accuracy_score
model = DecisionTreeClassifier(random_state=1)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)
-
현재는 ‘회귀’가 아닌 ‘분류’모델이기 때문에 MSE같은 값들로 검증하는 것이 아닌, y_test(검증데이터)와 pred(학습데이터 기반 예측값)을 비교함으로써 정확도를 검증한다.
-
DecisionTree는 언뜻 봤을 때, 난수가 생성될 포인트가 없어 보이지만, 애초에 모든 케이스를 돌려볼 수 없기 때문에 각 노드에서 분류할 컬럼을 난수를 통해 배정되는 것으로 보인다. 때문에, random_state값으로 고정해두지 않으면 매번 accuracy_score의 값이 달라진다. 이러한 문제를 이용하여 정확도를 극대화한 것이 랜덤 포레스트(Random-Forest) : 사실상 DecisionTree의 여러가지 묶음)이 되는 것 같다.
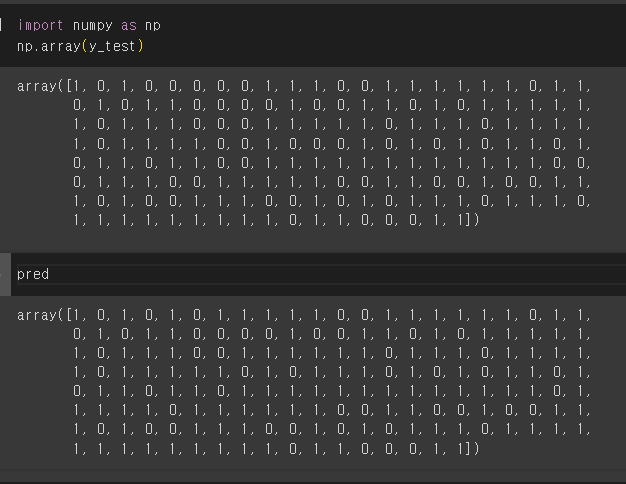
y_test와 pred의 각 0,1의 이진분류를 해놓은 결과값을 가지고 있고, 이를 비교하는 것이다.
✨ 사용되는 Hyperparameter 를 통해 정확도를 올릴 수 있다.
1) criterion = ‘entropy’
- 불순도 default = gini

출처 : Chat-gpt
- ☑️ 그럼 어떤 차이가 있는가?

출처 : Chat-gpt
2) max_depth = 4
- default = None 제한 깊이(노드 단계) ~ RootNode와 LeafNode의 단계차이 (모델의 복잡성 낮춤)
3) min_samples_split = 2
- default = None 분류하는 노드가 최소로 가져야 할 샘플 개수(value 개수)(과대적합 배제)
4) min_samples_leaf=2
- default = None 리프노드가 최소로 가져야 할 샘플 개수(value 개수) (과대적합 배제)
from sklearn.tree import DecisionTreeClassifier # 의사결정나무는 tree
from sklearn.metrics import accuracy_score
model = DecisionTreeClassifier(criterion = 'gini',
max_depth = 4,
min_samples_split = 2,
min_samples_leaf=2,
random_state=1)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)
- Hypter Parameter를 조정함에 따라 더 높은 정확성을 낼 수도 있다.
3. 앙상블(Ensemble)이란?
여러 개의 기본 모델을 조합하여 하나의 강력한 모델을 만드는 기계 학습 기법입니다. 이러한 기본 모델은 서로 다른 알고리즘을 사용하거나, 동일한 알고리즘을 다양한 설정으로 학습시켜 다양성을 확보하는 등의 방법으로 구성됩니다.
1) 보팅(Voting)
- 하드 보팅(Hard Voting): 다수결 원칙을 사용하여 각 모델의 예측 중 가장 많이 선택된 클래스를 최종 예측으로 선택
- 소프트 보팅(Soft Voting): 모델들의 예측 확률을 평균하여 가장 높은 확률을 가진 클래스를 최종 예측으로 선택
2) 배깅(Bagging)
- 부트스트랩 샘플링(Bootstrap Sampling)을 사용하여 각 모델을 다양한 데이터 부분집합으로 학습
3) 부스팅(Boosting)
- 이전 모델의 예측 오차에 초점을 맞추어 새로운 모델을 순차적으로 학습시키는 방식
4) 스태킹(Stacking)
- 다양한 기본 모델들을 훈련시킨 후, 이들의 예측 결과를 입력으로 사용하여 최종 모델을 학습
5) 랜덤 패치(Random Patches)와 랜덤 서브스페이스(Random Subspaces)
- 랜덤 패치: 훈련 데이터의 일부를 무작위로 선택하여 각 모델을 학습
- 랜덤 서브스페이스: 특성 중 일부를 무작위로 선택하여 각 모델을 학습
<출처 : Chat-gpt 3.5>
4. 랜덤 포레스트(RandomForest Classifier)란?
의사결정나무를 안다면 랜덤포레스트는 단순합니다. 의사결정나무를 여러번 시행하여 보다 정확하게 해당 값을 분류합니다. 앞전에 의사결정나무에 random_state 값을 지정하는 이유는 난수를 제어하기 위함입니다. 즉, 의사결정나무를 여러번 시행하면 다른 결과가 나오는 데 이것을 앙상블 기법 중 배깅을 차용하여 처리하는 것입니다. 때문에 코드에 n_estimator란 인자가 추가 되는 것외에 큰 차이가 없습니다.
from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트
model = RandomForestClassifier(
n_estimators= 100, # 만들 트리 개수
criterion = 'gini',
max_depth = 4,
min_samples_split = 2,
min_samples_leaf = 2,
random_state=1)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)
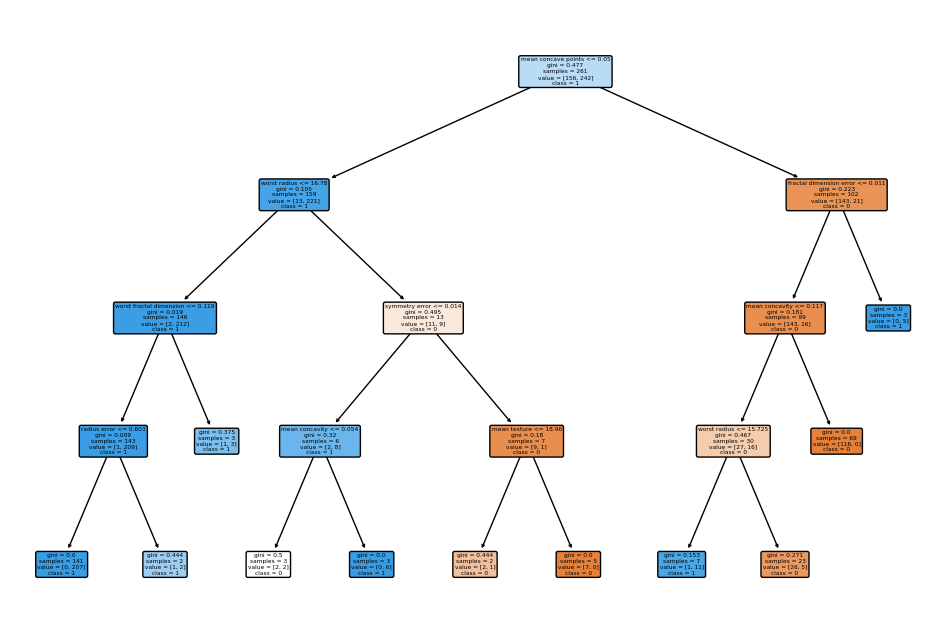
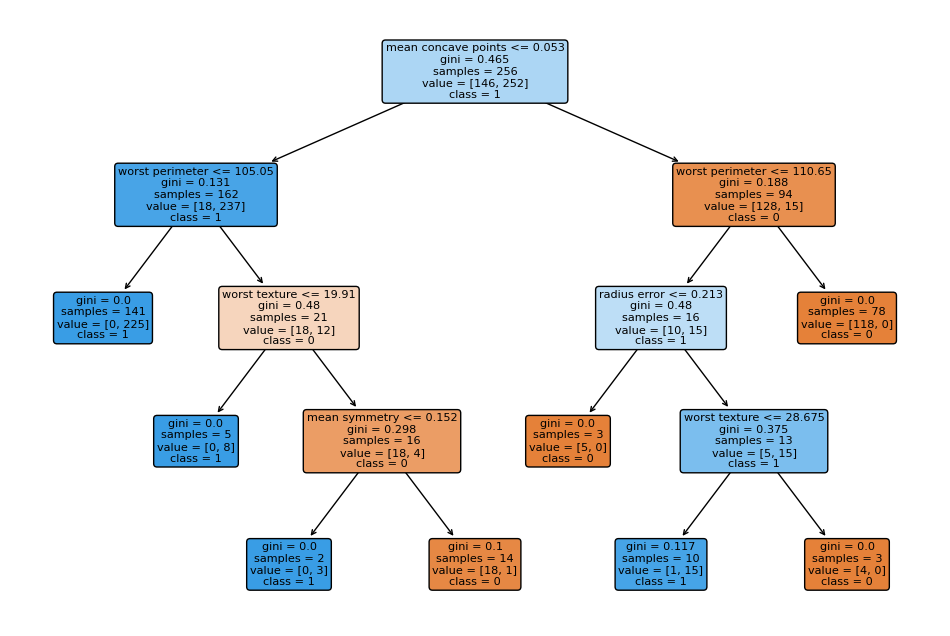
이를 3개만 시각화 해보면(관계상 1과 3의 그림만 남기겠다)
from sklearn.tree import export_text
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
selected_trees = model.estimators_[:3]
for i, tree in enumerate(selected_trees):
plt.figure(figsize=(12, 8))
plt.title(f"Decision Tree {i + 1}")
plot_tree(tree, feature_names=list(x_train.columns), class_names=['0', '1'], filled=True, rounded=True)
plt.show()
-
첫번째 의사결정트리
-
세번째 의사결정트리
5. XGBoost(eXtreme Gradient Boosting)란?
XGBoost는 랜덤포레스트와 마찬가지로 앙상블 기법 중 하나입니다. 결국 분류든 회귀든 단일 기본 모델들을 이용하여 더 나은 모델을 구성하고자 고안된 방법입니다. 첫번째 모델을 학습한 뒤, 예측값과 실제값의 차이를 계산하여 이를 예측 오차로 정의합니다. 이 예측 오차를 줄이는 목표를 가지고 학습을 반복합니다. 예측 오차를 정의하는 함수는 손실 함수인데, 분류 및 회귀에서의 손실 함수는 Chat-gpt에서 얻은 결과 아래와 같습니다.(eval_metric에 들어갈 인자들입니다.)
- 이진 분류 (Binary Classification):
- ‘error’: 이진 분류에서의 오분류율 (Error Rate)
- ‘logloss’: 로그 손실 (Logarithmic Loss)
- ‘auc’: ROC AUC (Receiver Operating Characteristic Area Under the Curve)
- 다중 클래스 분류 (Multiclass Classification):
- ‘merror’: 다중 클래스 분류에서의 오분류율 (Multiclass Error Rate)
- ‘mlogloss’: 다중 클래스 로그 손실 (Multiclass Logarithmic Loss)
- ‘softmax’: 다중 클래스 분류에서의 소프트맥스 로그 가능도 (Softmax Log Likelihood)
- 회귀 (Regression):
- ‘rmse’: 평균 제곱근 오차 (Root Mean Squared Error)
- ‘mae’: 평균 절대 오차 (Mean Absolute Error)
- Chat-gpt 3.5을 통해 추가적인 질문을 해본 결과 몇몇 로그 손실 함수들을 얻을 수 있었습니다.

이진 분류의 로그 손실 함수(출처 : Chat-gpt)

다중 클래스 분류의 로그 손실 함수(출처 : Chat-gpt)
다중 클래스 분류의 로그 손실 함수를 봤을 때, 조금 이상하다 생각되었습니다. yi가 왜 이진 표현이라 표현되어 있을까? 즉, 해당 손실 함수는 레이블의 인코딩 방식이 원-핫 인코딩 기준으로 사용될 때 기준이라 생각됩니다. 이 외의 방법으로 Chat-gpt 3.5로는 도저히 나오지 않아, Chat-gpt 4.0의 도움을 받아 질문해본 결과 또 다른 수식을 얻을 수 있었습니다.

- 크로스 엔트로피 로스(Cross Entropy Loss) 함수(출처 : Chat-gpt)
앞선 yi와는 달리 이진 지시자라는 표현이 쓰였고, 데이터 포인트의 수 시그마를 씌운 것으로 보아, 전체 데이터에서 각 데이터의 예측값=실제값이 같을 때의 확률을 로그로 씌워 합산한 것이라 보입니다. 즉 Pic의 값이 1이 된다면(실제값과 동일하게 예측할 확률이 1이 된다면) log1이 되어 해당 값은 0이 될 것입니다. 결국 모델의 정확도가 높을 수록 0에 가까운 수치가 된다는 말입니다. 이 손실 함수에선 레이블 인코딩일지라도 해당 수식에선 0, 1, 2, 3 등의 값이 아무런 의미를 지니지 못할 것입니다. 이를 이해하고 모델에 적합한 손실 함수를 이용하는 것이 매우 중요할 듯합니다.
또한 XGBoost에선 학습률(learning_rate)란 개념이 중요한 데, 예측 오차에 대한 개선 사항을 강하게 적용하게 되면 과대적합(Overfitting)의 문제가 발생해 모델 자체가 일반화하기 힘든 모델이 됩니다. 즉, 미확인 데이터에 대해 정확히 예측을 수행할 수 없기 때문에 이는 사용자가 직접 조정해보며 시행착오를 겪어봐야하는 중요한 수치입니다. 사실 머신러닝의 코딩자체는 어려운 문제는 아니기 때문에, 하이퍼 파라미터의 의미를 얼마나 잘 이해하는가가 중요한 문제라고 생각됩니다.
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
model = XGBClassifier(random_state=0, use_label_encoder=False,
eval_metric='logloss', # 기준이 되는 손실함수
booster = 'gbtree', # 부스팅 알고리즘 (또는 dart, gblinear)
objective = 'binary:logistic', # 이진분류 (다중분류: multi:softmax)
max_depth = 5, # 노드의 최대깊이
learning_rate = 0.05, # 학습률(최대 값 1)
n_estimators = 500, # 트리수
subsample = 1, #샘플 비율(최대 값 1) 0.8이면 모집단의 80%를 랜덤샘플링 학습, 1은 전체 (낮을 수록 과적합 확률 낮음)
colsample_bytree = 1, # 특성(데이터의 컬럼들)을 랜덤 선택하는 비율, 0.7이면 각 트리마다 70%의 특성으로 학습.
n_jobs = -1) # 작동할 코어 수 -1은 전체
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)
subsample, colsample_bytree도 마찬가지입니다. 한 개의 트리가 구성하는 샘플 수(줄 개수) 또는 특성 수(컬럼 개수) 등을 조절하여 모델이 학습데이터에 과적합(overfitting)되는 것을 방지합니다.
이제 시각화를 해보겠습니다.
from xgboost import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 20))
plot_tree(model, num_trees=0, rankdir='LR')
plt.show()
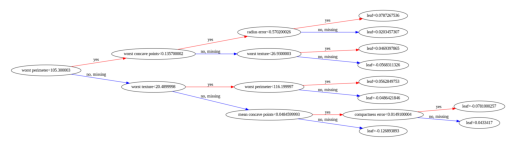
시각화 결과(잘보이지도 않으나 이이상 확대가 잘 안되는 듯 하다)
6. 이진 분류 모델(binary classification) 여러 가지 평가 지표
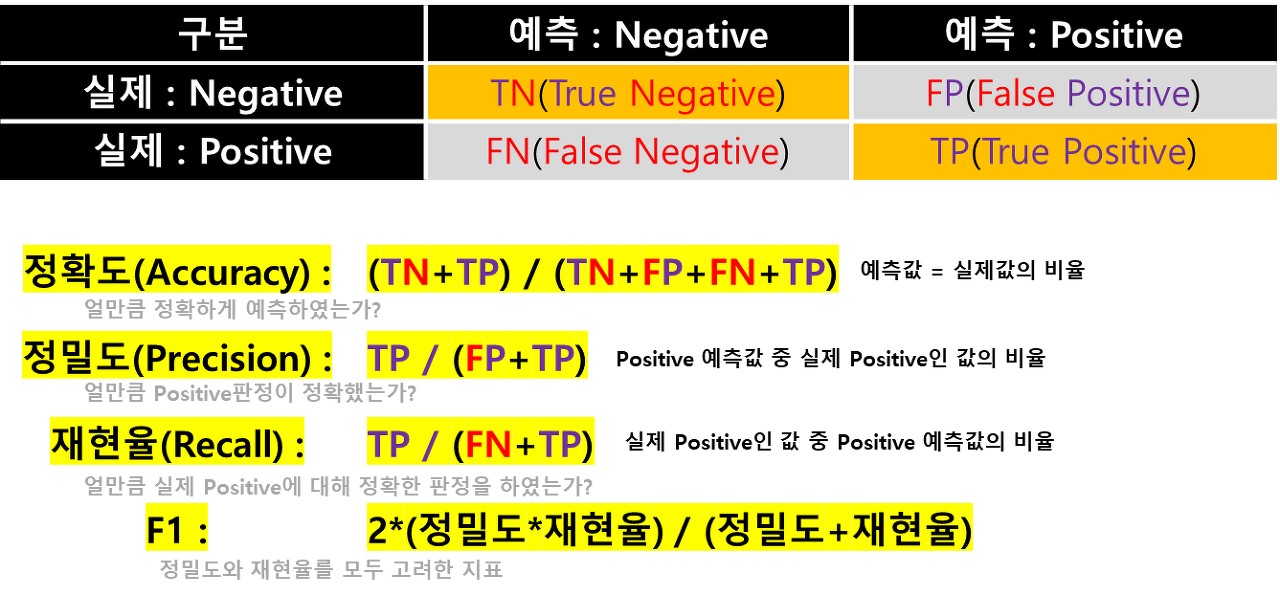
각 지표들은 무엇이 중요한 가에 따라 달라진다. 예를 들어 스팸 메일을 판단할 때, “실제 일반 메일임에도, 스팸이라 판정하는 비율" 즉, FP의 값이 줄어야만 한다. 즉 이때 정밀도(Precision)의 값이 중요한 판단 지표가 될 수 있다. 이 외에도 FN의 값을 줄여야 하는 재현율(Recall) 등, 이 둘 모두를 고려한 F1 등 여러가지 지표들이 많다. 실제 상황에 어떤 판단이 중요할 지를 고려하여 모델링을 잘해야 한다.
✨ 소감 : 구글링으로 여러번 시도 해보았으나.. 영어로 쳐도 개인 블로그만 너무 나오고 Chat-gpt는 은근히 오류투성이라.. 어떤 자료를 믿고 학습을 해야할 지 고민된다…..
댓글남기기