Scikit-learn(비지도학습) - 군집화
✨ 샘플데이터
from sklearn.datasets import load_wine
import pandas as pd
dataset = load_wine()
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df = data.copy()
✨ 데이터 전처리
# 표준화 스케일링
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = scaler.fit_transform(data)
df = data.copy()
# PCA 2차원 축소
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
df = pca.fit_transform(df)
df = pd.DataFrame(df)
1. 비계층적 군집분석 : 군집의 수를 가장 먼저 선정
- 중심값으로 떨어져있는 거리를 토대로 군집화, 초기 중심 값은 임의로 선정하며, 중심 값이 이동함
1) KMeans
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(df)
pred = kmeans.predict(df)
- 모델을 만들 때 별 다른 것은 없다. n_clusters 파라미터 즉, 군집의 수만 지정해주어도 모델을 생성할 수 있다.
- 시각화를 해보면 결과를 볼 수 있다.
df['pred'] = pred
centers = kmeans.cluster_centers_
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,6))
sns.scatterplot(x=df.iloc[:,0], y=df.iloc[:,1], hue=df['pred'])
plt.scatter(centers[:,0], centers[:,1])])
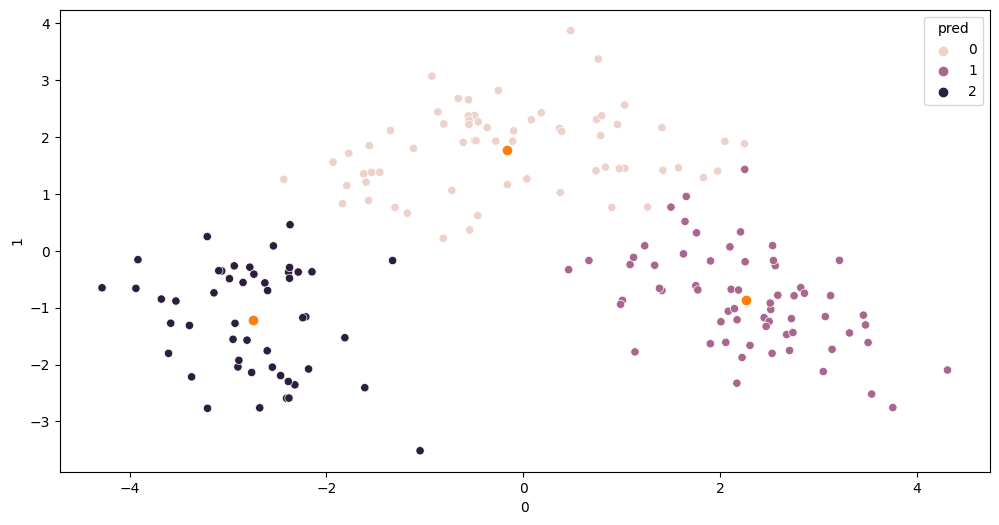
주황색은 중심 값이다.
✨ 실제값과 예측값 비교
df["target"] = dataset.target
df.groupby(["target","pred"])['pred'].count()
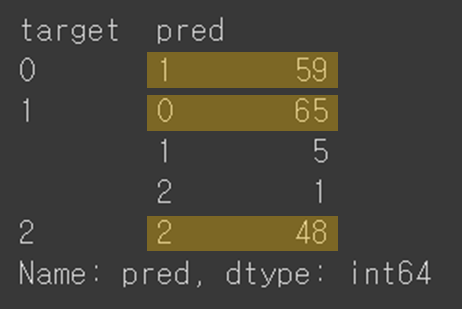
0은 1, 1은 0, 2는 2로 서로 조금 다른 것을 확인할 수 있다.
범주의 값은 무작위로 선정되기 때문에, target의 0이 pred의 0과 다를 수 있음을 주의하여야 한다.
✨ 군집화 갯수 정하는 팁
inertia = []
for i in range(1, 10) :
kmeans = KMeans(n_clusters=i, random_state=1) # 초기 중앙값 고정
kmeans.fit(df)
inertia.append(kmeans.inertia_)
plt.plot(range(1,10), inertia)
군집별로 inertia_값(중심값과 군집 데이터들간의 거리차 제곱)을 도출해본다. random_state는 초기 중앙값을 고정하기 위해 넣는다. 적정선의 군집 수를 정하면 된다.
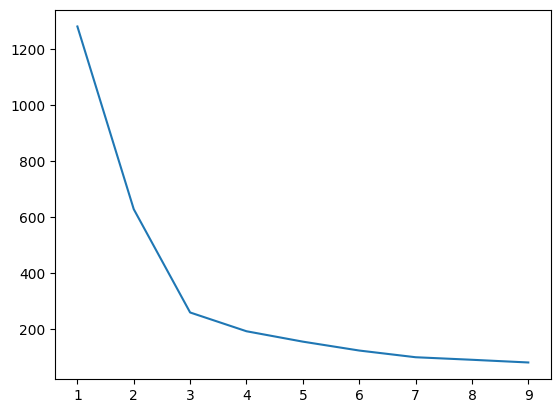
4~6정도에서 군집을 선택하면 좋을 듯 하다.
2. 계층적 군집분석(전통적) : 군집의 수를 나중에 선정
kdata = df[:3]
kdata = kdata.append(df[70:73])
kdata = kdata.append(df[170:173])
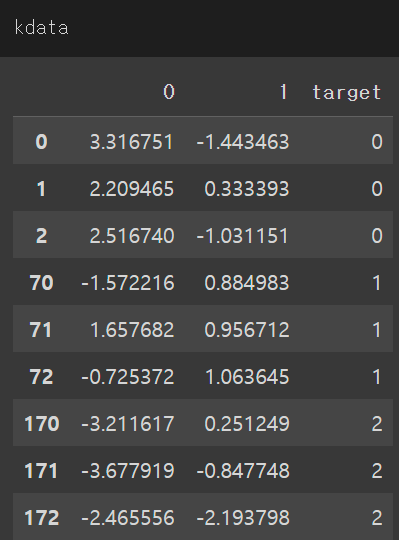
결과가 각 0, 1, 2인 데이터 몇개를 추출해본다.
✨ 덴다이어그램 그리기
from scipy.cluster.hierarchy import dendrogram, ward
linkage = ward(kdata)
dendrogram(linkage)
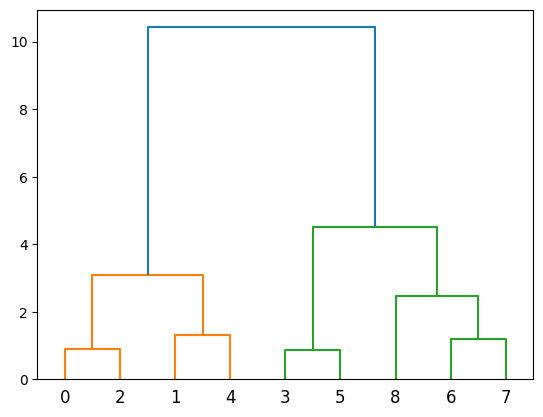
군집화된 모습
댓글남기기