Scikit-learn(지도학습3) - 자연어처리
✨ 과연 인간은 기계에게 언어를 학습시킬 수 있을까요?
- 그렇다면 첫 번째로 인간이 언어를 이해하기 위해서 무엇을 배웠는가? 바로 “단어”이다. 그렇기에 의미를 가지는 최소한의 단위인 “형태소”를 컴퓨터에 먼저 학습시키는 것이다.
CountVectorizer, TfidVectorizer는 이 형태소를 어떠한 방법으로 학습시키는 지로 나뉜다.
먼저 형태소를 만드는 법 알아보면, 대표적인 것 중 하나로 Konlpy툴을 이용하면 된다.
! pip install konlpy
설치를 한 뒤,
text = "안녕하세요! I'm happy예요"
import konlpy
from konlpy.tag import Okt
tokenizer = Okt()
tokenizer.morphs(text)

한글, 특수문자, 영어까지 구분된 모습
이런 형태소를 어떻게 학습하느냐에 따라 두 가지 방법으로 갈린다. 이 후 알아보기 위해, 다음의 예시자료를 이용하고자 한다.
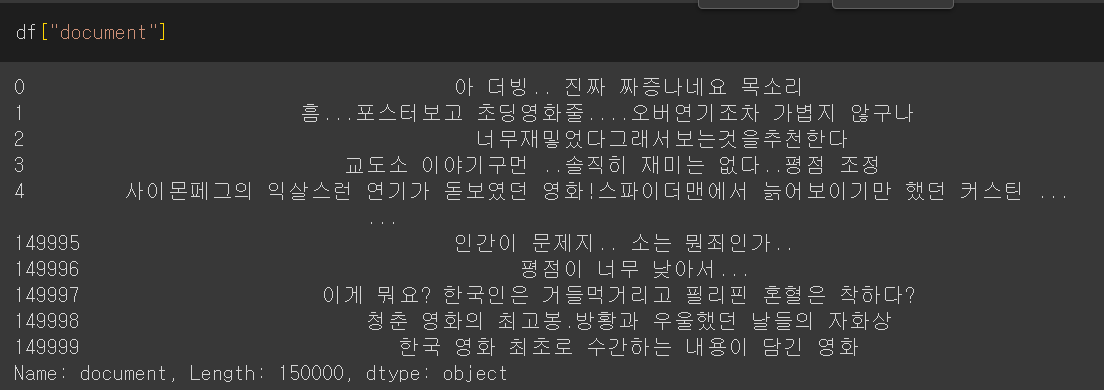
학습할 예시 데이터
1. CountVectorizer

장점과 단점
단순히 단어의 빈도만으로 벡터화시키는 도구이다. 1000개의 문장만 학습해보도록 하자
from sklearn.feature_extraction.text import CountVectorizer
CV_model = CountVectorizer(tokenizer=tokenizer.morphs)
vectors = CV_model.fit_transform(df.loc[:1000,"document"])
학습된 단어장을 보면 단어들이 학습되고
CV_model.vocabulary_

상당히 많은 단어가 학습된 모습
vectors.toarray()
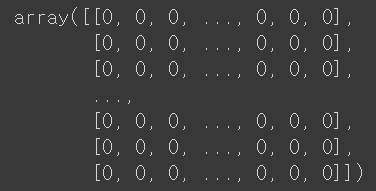
각 단어들이 원핫코딩처럼 전처리된 것을 알 수 있다.
✨ 어떤 의미인가 시각화를 해보면
df_CV_model = pd.DataFrame(data=vectors.toarray(), columns = CV_model.get_feature_names_out())
df_CV_model
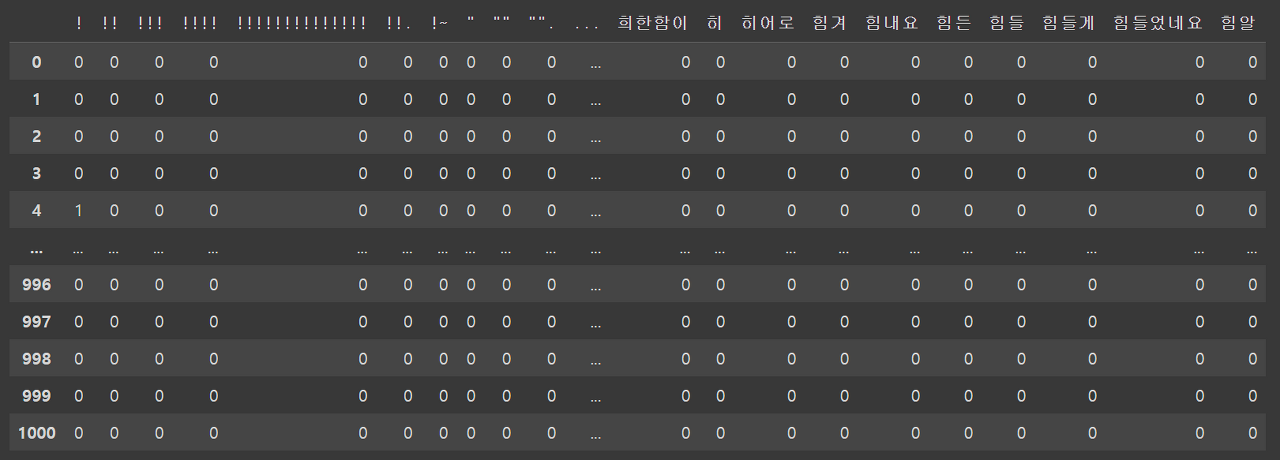
각 형태소별로 수많은 컬럼으로 이루어진 1000개의 줄을 가진 데이터를 가지고, 안에는 해당 형태소의 수의 빈도 값이 채워져 있다.
이를 랜덤포레스트를 통한 k-fold교차 검증을 진행하여 f1스코어를 도출해보면 다음과 같다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
model = RandomForestClassifier(random_state=2022)
cross_val_score(model, vectors, df.loc[:1000, 'label'], scoring='f1', cv=5)
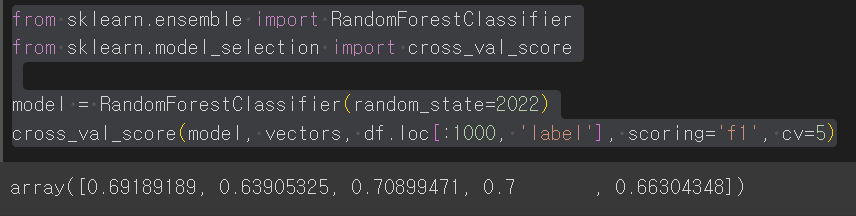
70%정도로 긍정 문장인지 부정 문장인지 맞추고 있다고 볼 수 있다.
그렇다면 정확도를 올릴 수 있는 방법은 없는가? 단순하다. CounterVectorizer보다는, TfidfVectorizer가 감정 분석에 유리하고 의미가 없는 불용어(은, 는, 이, 가)를 정리하거나 띄어쓰기, 맞춤법 등을 고려할 수 있다.
띄어쓰기나 맞춤법은 (hanspell라이브러리의 spell_checker메서드가 있다. 하지만 현재 오류가 발생한 상태이나 타인에 의해 수정된 버전을 merge해주지 않아, 따로 예시를 들지않고 불용어만 정리하는 법을 다음에 제시하겠다.
2. TfidVectorizer

장점과 단점


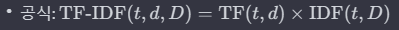
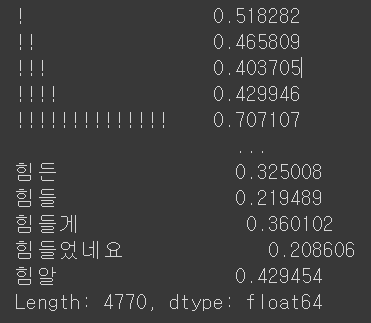
위와 같은 수식을 통해 가중치가 결정되어, 전체적으로 희소한 단어는 높은 가중치를, 문장 내에서 빈도가 높은 단어에 높은 가중치를 엮어서 주는 형식으로, 단순히 전체적으로 빈도가 높고 문장 내에서 빈도가 높은 단어의 가중치는 낮아진다.
from sklearn.feature_extraction.text import TfidfVectorizer
TF_model = TfidfVectorizer(tokenizer=tokenizer.morphs, max_df=5, min_df=2)
vectors = TF_model.fit_transform(df.loc[:1000,"document"])
df_TF_model = pd.DataFrame(data=vectors.toarray(), columns = TF_model.get_feature_names_out())
df_TF_model.max()
max값을 도출해보면 빈도수가 아닌 위 수식에 따라
✨ 출연 빈도에 제한을주면 달라진 결과를 볼 수 있다.
from sklearn.feature_extraction.text import TfidfVectorizer
TF_model = TfidfVectorizer(tokenizer=tokenizer.morphs, max_df=5, min_df=2, stop_words=["은","는","이","가"])
vectors = TF_model.fit_transform(df.loc[:1000,"document"])
- max_df 숫자, 여기선 5문장 이상에서 발견되면 무시 / 1이하의 숫자를 적을 시 해당 비율 이상의 문장에서 발견되면 무시
- min_df 숫자, 여기선 2문장 이하에서 발견되면 무시 / 1이하의 숫자를 적을 시 해당 비율 이하의 문장에서 발견되면 무시
df_TF_model = pd.DataFrame(data=vectors.toarray(), columns = TF_model.get_feature_names_out())
df_TF_model.max()
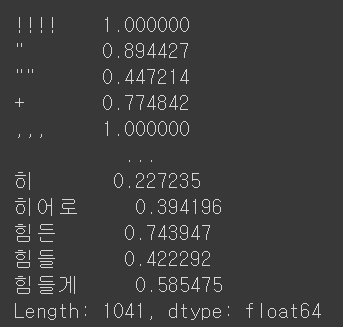
!, !! 등이 사라진 것을 볼 수 있다.
max_df 또는 stop_words 통해 모든 문장에 자주 등장할 “은, 는, 이, 가” 등의 조사를 쉽게 제거할 수 있고 반대로 min_df를 통해 틀린 맞춤법 등을 제거할 수 있으나, 실제로 편향된 학습으로 불용어가 아닌 형태소를 삭제시키거나 맞춤법이 맞으나 출연 빈도가 낮은 전문용어를 제거할 수 있어 사용에 유의를 해야한다.
실제로는 띄어쓰기, 맞춤법 등의 전처리를 한 뒤, 형태소 분리를 하고 "은, 는, 이, 가"등의 불용어를 제거해나가는 절차를 밟는 것이 좋을 것이다.
댓글남기기