Pandas의 기초3 - 데이터 가공(데이터프레임 복사 / 데이터 삭제, 결측치 다루기)
✨ 복사의 두 종류
- 얕은 복사(shallow copy) ~ data = df [data가공 시 원본 데이터인 df까지 변경될 수 있다.]
- 깊은 복사(deep copy) ~ data = df.copy() [서로 개별적으로 인식되어 가공하여도 df가 변경되지 않는다.]
1. 데이터 깊은 복사 : df.copy()
# 결측치 존재하는 데이터
df = pd.read_csv("https://raw.githubusercontent.com/NeatyNut/csv/main/sample2_csv.csv")
data = df.copy()
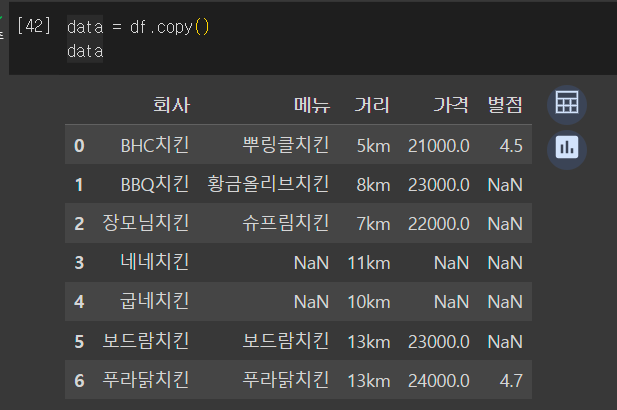
보다시피 동일한 데이터를 복사하여 새로운 data라는 사본 데이터프레임을 만든다.
2. 데이터 삭제 : [행 삭제] df.drop(인덱스번호, axis=0) [컬럼 삭제] df.drop(“컬럼명”, axis=1)
1) 행 삭제
data = data.drop(5, axis=0) # axis는 생략가능
data
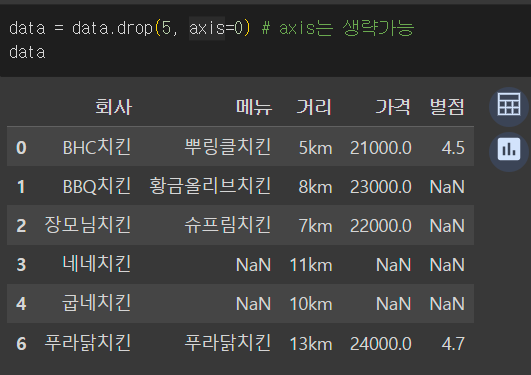
5번 인덱스 행이 삭제된 걸 확인할 수 있다.
- ✨ 인덱스를 리스트로 담아도 사용 가능
data = data.drop([1,2], axis=0) # axis는 생략가능 data
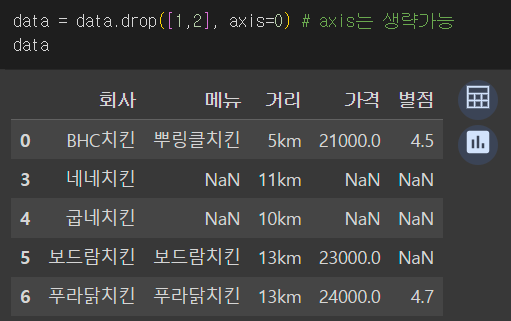
삭제할 인덱스를 리스트로 담아서도 삭제가능하다.
2) 열 삭제
data = data.drop("거리", axis=1)
data
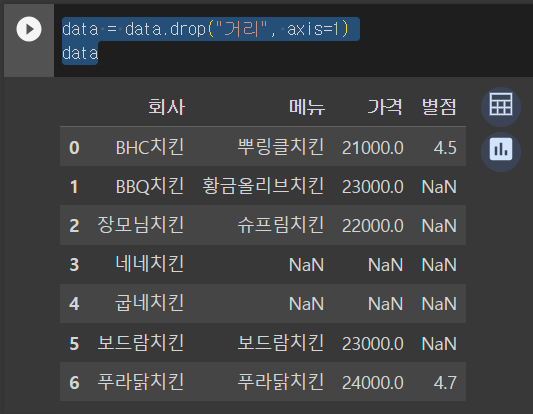
컬럼 “거리”를 삭제한 모습
- ✨ 동일하게 리스트에 담아서 삭제 가능
data = data.drop(["거리","별점"], axis=1)
data
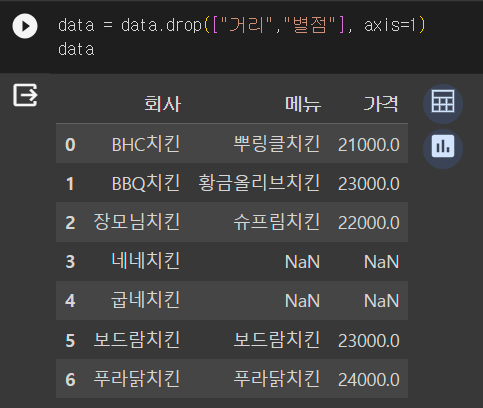
거리, 별점을 삭제한 모습
3. 데이터 결측치 다루기
1) 결측치 확인 : isnull()
data.isnull() # 컬럼별 T/F 변환 ~ Null이면 T
data.isnull().sum() # 컬럼별 널값 숫자 확인 T=1/F=0인걸 이용하여 합산.
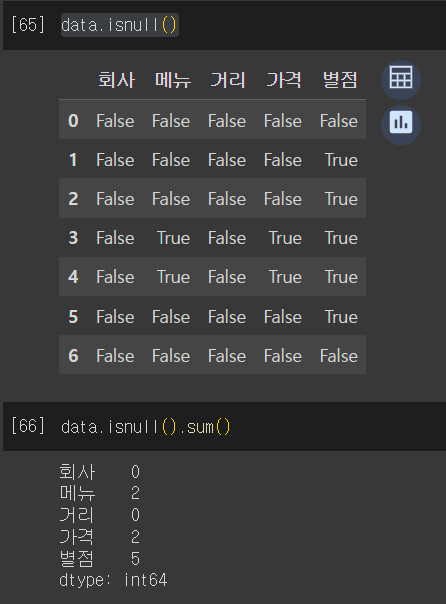
두가지 방법을 통해 Null의 위치 또는 개수를 알 수 있다.
- ✨ T 또는 Transpose() 를 하여 전치하면 행별 결측치 개수 또한 쉽게 확인 가능하다.
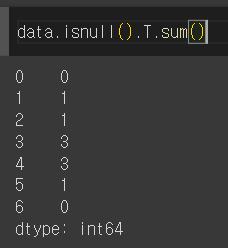
Index별 결측치 개수
2) 결측치 채우기 : fillna()
data["별점"] = data["별점"].fillna(3) # 별점의 결측치를 3으로 채움
data
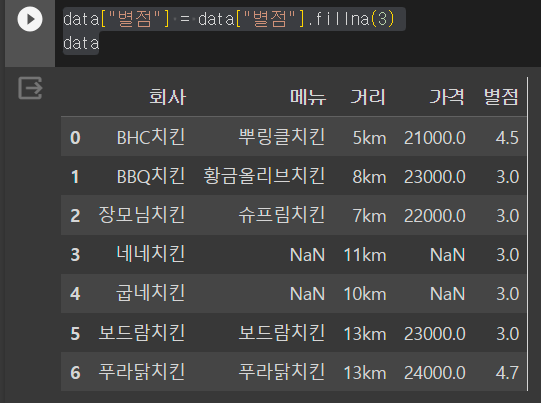
Nan이었던 별점이 3으로 채워진 모습
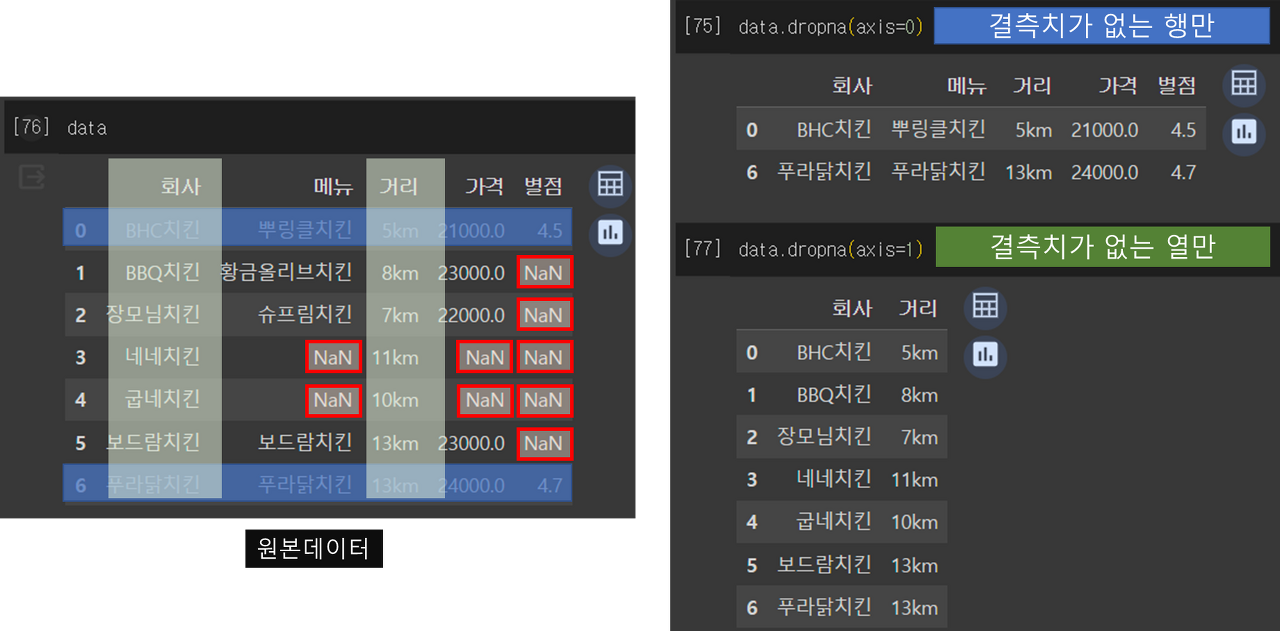
3) 결측치 삭제하기 : dropna()
data = data.dropna(axis=0) # 행 기준(axis 생략가능)
data = data.dropna(axis=1) # 열 기준
댓글남기기