SQL 엑셀로 이해하기(기초2) - 집계함수, Groupby
SQL문 사용할 사이트 : MySQL Tryit Editor v1.0 (w3schools.com)
1. 집계함수(sum, average, count 등)
- 엑셀에서 ProductID가 1인 것의 개수가 궁금하다면 필터를 써서 개수를 세어본다. SQL도 마찬가지이다. 필터 즉, where절을 이용하면 된다.
- ProductID가 1인 데이터의 개수를 알아보자.
SELECT Count(*) FROM OrderDetails where ProductID = 1;
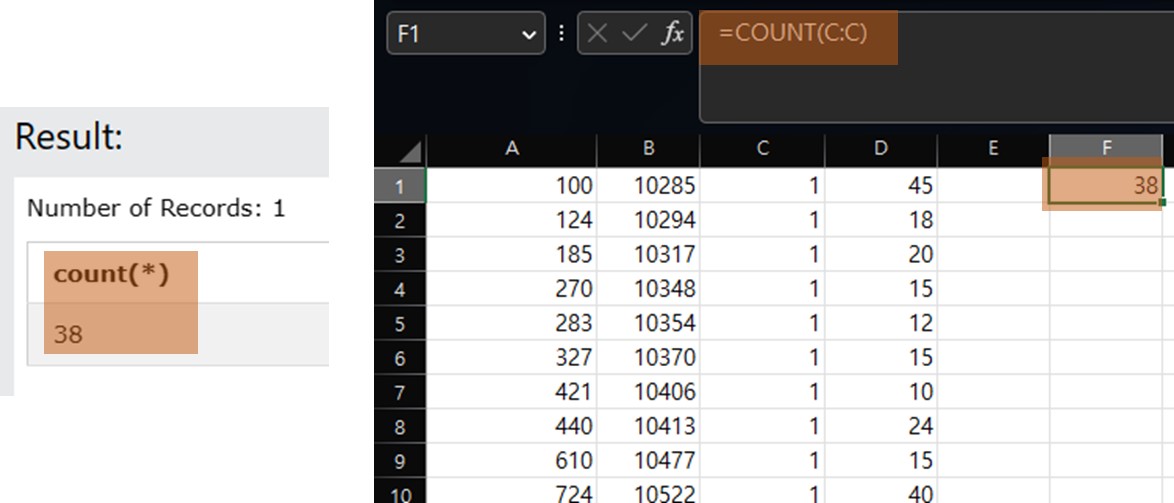
똑같이 38개를 가져오는 것을 볼 수 있다.
- ✨잠깐, *는 모두를 뜻한다고 했는데, 왜 38X4인 152개 아닌, 38개인가? 이는 SQL문은 일반적으로 각 컬럼 간의 연산이 중요치 않고 하나의 줄을 하나의 데이터로 인식하는 경향이 있는 듯하다.. 실제로, Count와 달리 SUM이나, AVERAGE처럼 각 칼럼별 수치가 달라질 때는 구체적인 컬럼명을 넣어주지 않으면 오류가 일어난다.
- ✨ Syntax error(구문 오류)가 일어남
SELECT SUM(*) FROM OrderDetails where ProductID = 1;

Syntax error
- ✨✨ 구체적인 컬럼명을 지칭한 경우
SELECT SUM(Quantity) FROM OrderDetails where ProductID = 1;
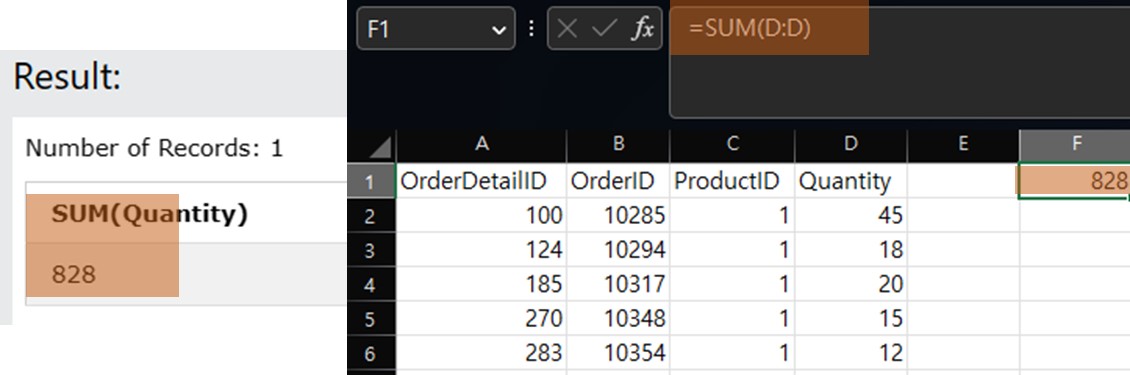
D열, 즉 Quantity컬럼의 합산이 동일하게 나타나는 것을 볼 수 있다.
그렇다면 엑셀처럼 A2:D2라는 횡적인 합산은 불가능한가? 아니다. 당연히 가능합니다.
SELECT (OrderDetailID + OrderID + ProductID + Quantity) as "합산" FROM OrderDetails where ProductID = 1;
- ✨ 내장함수는 없는 듯 하나, +,-,*,/ 등 컬럼간의 사칙연산은 충분히 가능합니다.
- as의 뜻은 앞으로의 구문에서 해당 데이터셋(컬럼 또는 테이블)을 "합산"으로 칭하겠다는 뜻입니다.
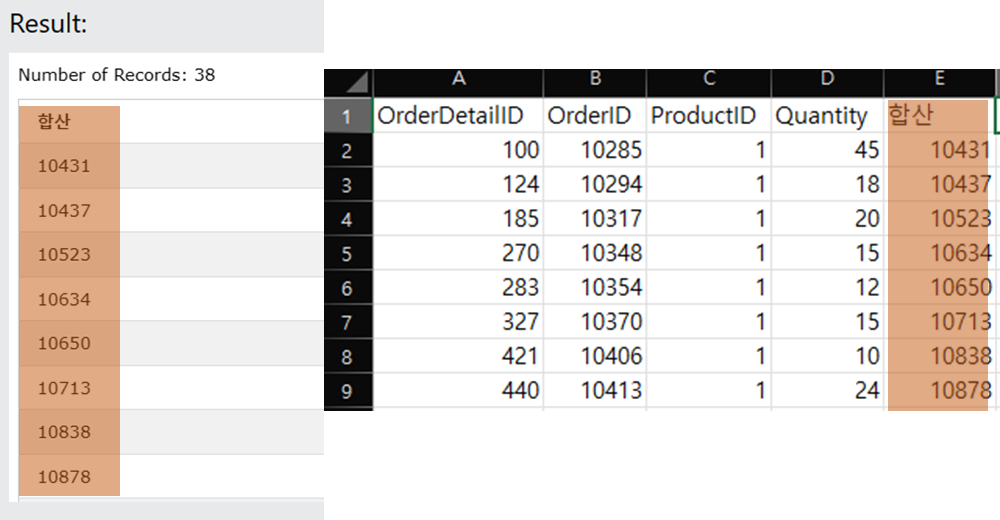
합산이라는 컬럼이 생성되어 동일한 결과가 들어오는 것을 알 수 있습니다.
엑셀처럼 E열에 붙일 순 없냐구요? 물론 가능합니다. 모든 컬럼을 뜻하는 *만 앞에 붙여주세요.
SELECT *, (OrderDetailID + OrderID + ProductID + Quantity) as "합산" FROM OrderDetails where ProductID = 1;
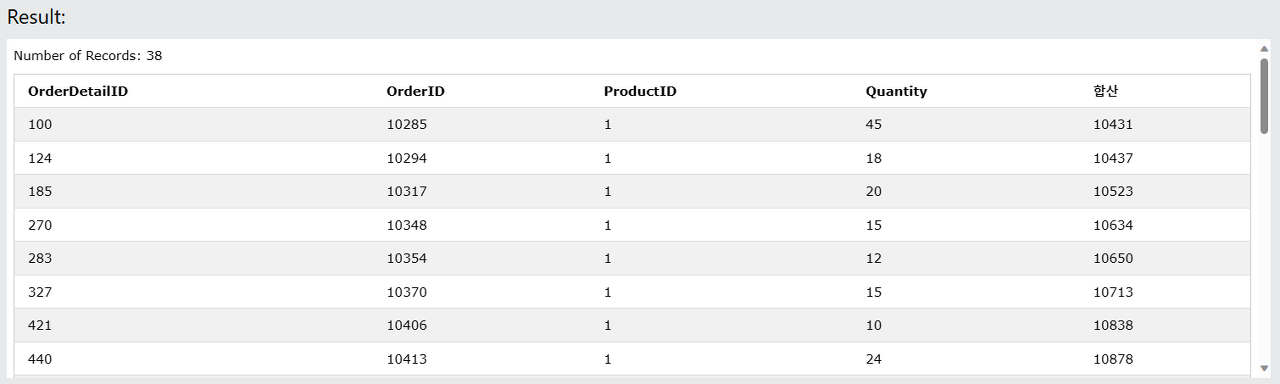
엑셀과 동일한 테이블이 되었습니다.
이를 통해, 기존 테이블을 활용하여 새로운 컬럼들을 생성할 수 있음을 알 수 있었습니다.
사실 어느 누가 엑셀에서 여러개의 컬럼을 필터링해가며 조건마다 합계 내어 하나요? 그런 사람들을 위해 피벗테이블이 있습니다. 물론 SQL피벗테이블 내 모든 기능을 할 순 없지만, 동일한 그룹별로 집계를 낼 때 GROUP BY를 활용합니다.
2. GROUP BY(집계 기준), HAVING(집계 조건)
- GROUP BY는 엑셀에서 생각할 때 피벗테이블을 생각하면 쉽습니다. 그렇게 생각하면 흔히들 GROUP BY절에서 WHERE문과 HAVING문이 둘다 조건문이라 많이들 헷갈려 하시는데요. 일단 예시문을 하나 비교하시겠습니다.
SELECT ProductID, SUM(Quantity) FROM OrderDetails
WHERE OrderID > 10270
GROUP BY ProductID
HAVING ProductID <= 10;
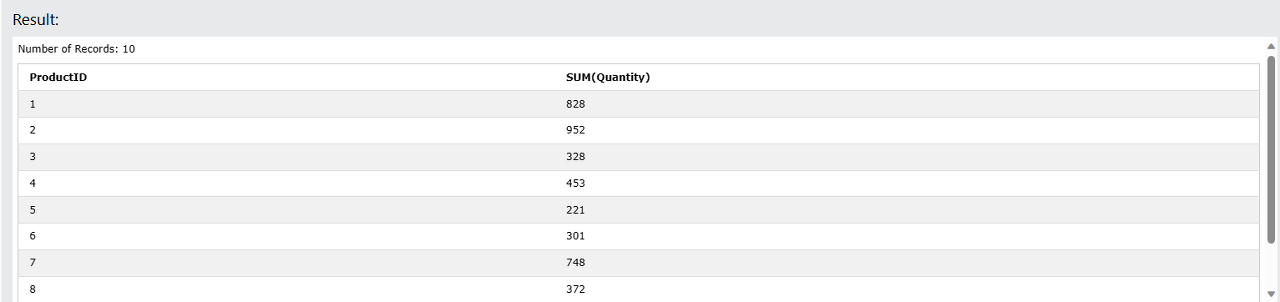
ProductID기준으로 그룹화를 한 뒤, SUM(Quantity)로 집계값을 쓴다.
- 이를 피벗테이블으로 표현하면 아래와 같습니다.
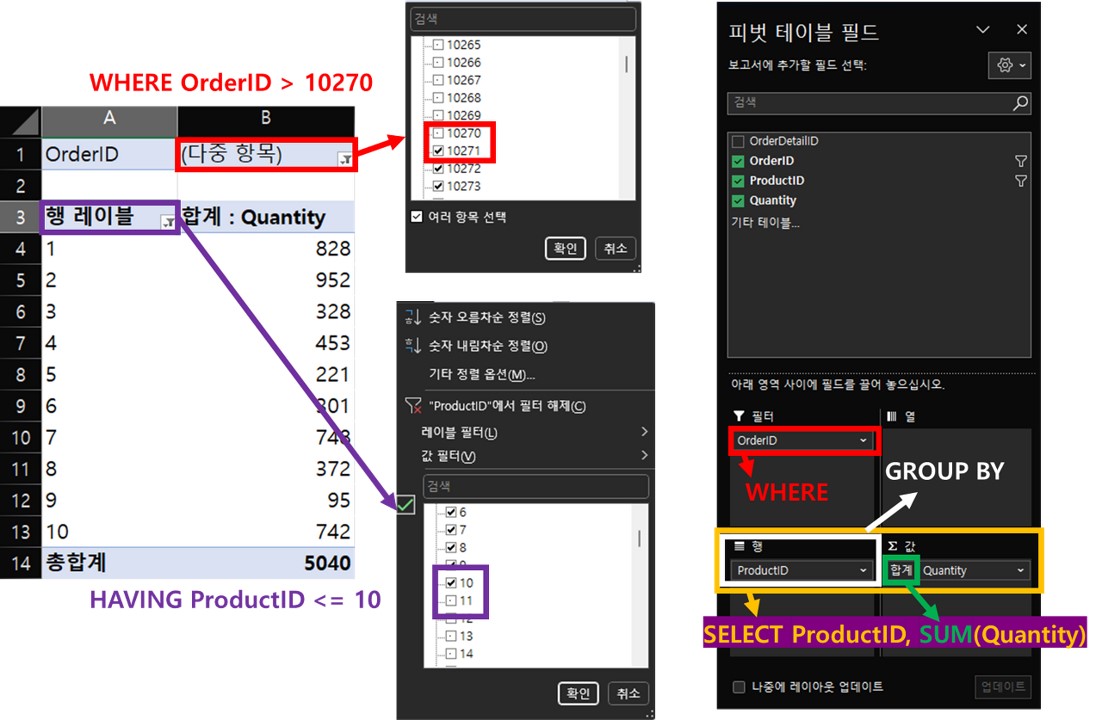
피벗테이블로 대응된 각 명령어
즉, SELECT ProductID, SUM(Quantity) FROM OrderDetails 은
- “OrderDetails” 테이블을 원본으로 한 피벗테이블을 만든다.
- 첫 행기준으로 ProductID가 온다.
- 값으로 Quantity를 갖는 데, SUM 즉, “합계” 정보를 가지고 싶다.
라 해석됩니다.
사실상, GROUP BY은 피벗테이블에서 “행”에 대응되고, 집계함수 값들은 “값”에 대응됩니다.
WHERE OrderID > 10270와 HAVING ProductID <= 10 모두 조건 절이지만, WHERE은 집계하기 전 필터링하는 데 반해, HAVING 집계한 후의 데이터에서 필터링을 한다.
라고 보시면 됩니다.
즉, WHERE절은 집계 되는 원본 테이블에서 필터링을 하기에, 집계 값에 영향을 끼칠 수 있는 반면, HAVING은 집계된 표를 기준으로 가지는 필터링이라, 집계 값을 변경시키진 못합니다.
집계된 표가 기준이기에, GROUP BY 기준 컬럼들, 집계함수의 대상인 컬럼이 아니면 HAVING절은 오류가 발생합니다.
SELECT ProductID, SUM(Quantity) FROM OrderDetails
WHERE OrderID > 10270
GROUP BY ProductID
HAVING OrderID <= 10;
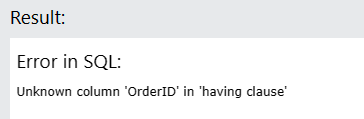
알 수 없는 컬럼이라 뜹니다.
반면 아래의 코드는 Quantity 합계 즉, “값”에 해당하는 부분이기에 문제없이 결과를 도출합니다.
SELECT ProductID, SUM(Quantity) FROM OrderDetails
WHERE OrderID > 10270
GROUP BY ProductID
HAVING SUM(Quantity) <= 100;

유일하게 100보다 작은 ProductID 9의 데이터만 도출된다.
또한 피벗테이블과 동일하게 두개 이상의 GROUP BY 또한 가능하다.
SELECT ProductID, OrderDetailID, SUM(Quantity) FROM OrderDetails
GROUP BY ProductID, OrderDetailID
HAVING ProductID <= 10 AND OrderDetailID < 100;
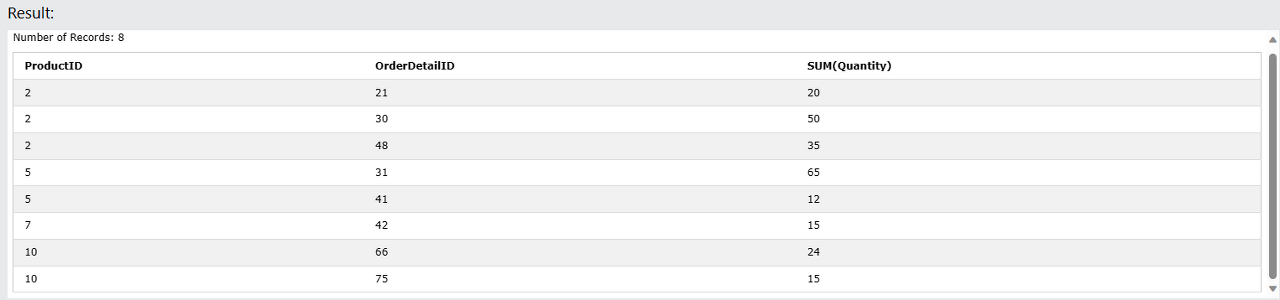
두개 이상의 기준과 두개 이상의 HAVING 구문도 가능합니다.
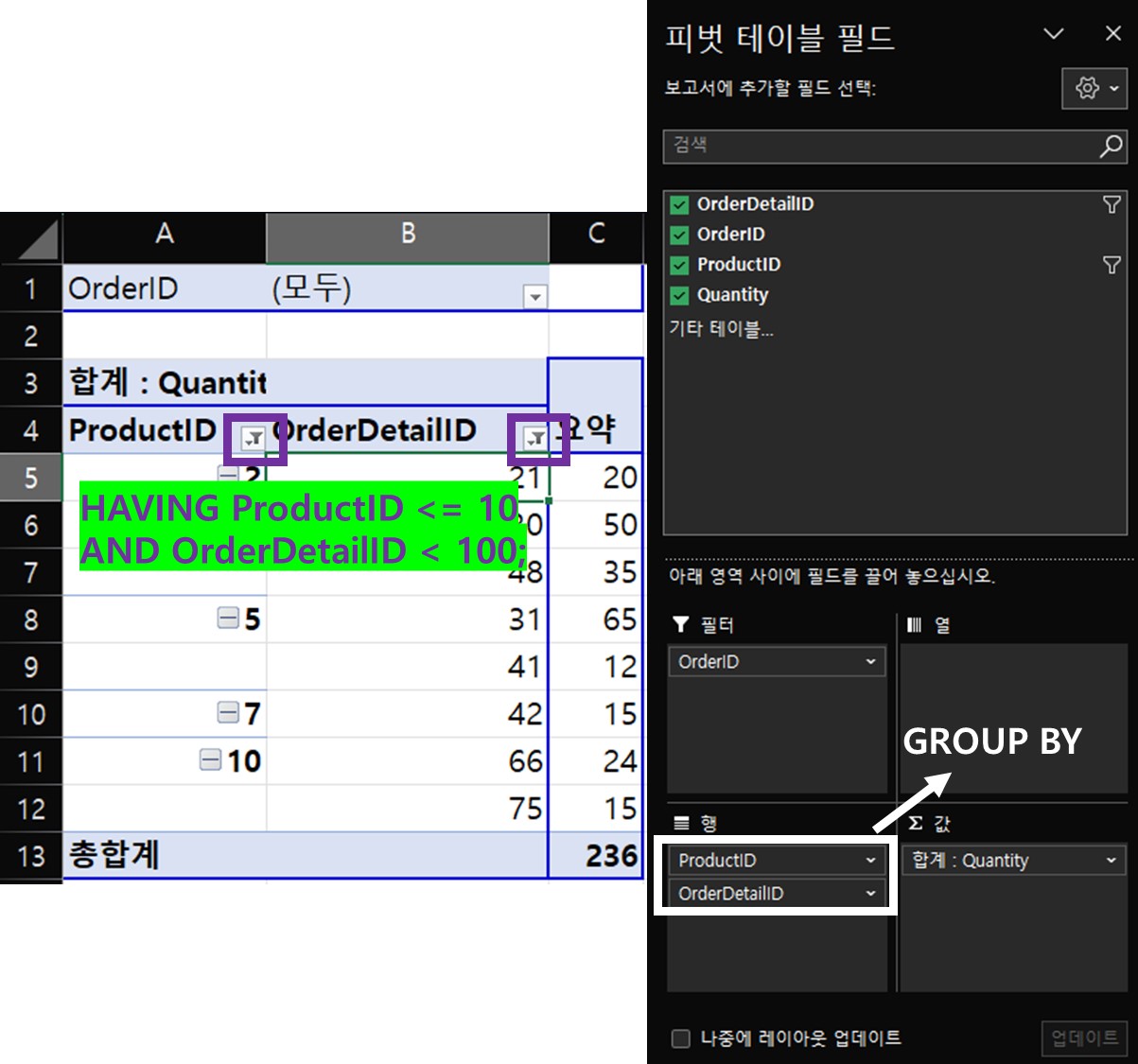
위의 SQL과 동일한 작용을 하는 피벗 테이블은 위와 같다.
댓글남기기